
Han pasado más de 7 meses desde que publicamos nuestra última precisión de reconocimiento de voz punto de referencia. En aquel entonces, los resultados eran los siguientes (del más preciso al menos preciso): Microsoft y Amazon (casi en segundo lugar), luego Voicegain y Google Enhanced, y luego, muy por detrás, IBM Watson y Google Standard.
Desde entonces, hemos obtenido más datos de formación y hemos añadido funciones adicionales a nuestro proceso de formación. Esto se tradujo en un aumento adicional en la precisión de nuestro modelo.
En lo que respecta a los demás reconocedores:
Hemos decidido dejar de informar sobre la precisión de Google Standard e IBM Watson, que siempre estuvieron muy por detrás en cuanto a precisión.
Hemos repetido la prueba con una metodología similar a la anterior: utilizamos 44 archivos del Conjunto de datos de Jason Kincaid y 20 archivos publicado por rev.ai y eliminó todos los archivos en los que ninguno de los reconocedores podía alcanzar una tasa de errores de palabras (WER) inferior al 25%.
Esta vez solo un archivo fue tan difícil. Fue una entrevista telefónica de mala calidad (Entrevista a Byron Smith (111416 - YouTube).
Puedes ver diagramas de caja con los resultados de arriba. El gráfico también muestra el promedio y la mediana de la tasa de errores de palabras (WER)
Todos los reconocedores han mejorado (el modelo de Google Video Enhanced se mantuvo prácticamente igual, pero Google ahora tiene un nuevo reconocedor que es mejor).
Google, de última generación, Voicegain y Amazon están ahora muy cerca, mientras que Microsoft es mejor en aproximadamente un 1%.
Veamos la cantidad de archivos en los que cada reconocedor era el mejor.
Tenga en cuenta que los números no suman 63 porque había algunos archivos en los que dos reconocedores arrojaban resultados idénticos (con 2 dígitos detrás de una coma).
Ahora hemos realizado el mismo punto de referencia 4 veces para poder dibujar gráficos que muestren cómo cada uno de los reconocedores ha mejorado en los últimos 1 año y 9 meses. (Ten en cuenta que para Google el último resultado proviene del modelo más reciente y otros resultados de Google provienen de vídeos mejorados).
Puedes ver claramente que Voicegain y Amazon empezaron bastante por detrás de Google y Microsoft, pero desde entonces se han puesto al día.
Google parece tener los ciclos de desarrollo más largos, con muy pocas mejoras desde septiembre de 2021 hasta hace muy poco. Microsoft, por otro lado, lanza un reconocedor mejorado cada 6 meses. Nuestras versiones mejoradas son incluso más frecuentes que eso.


Como puede ver, el campo está muy cerca y se obtienen resultados diferentes en diferentes archivos (el promedio y la mediana no muestran el panorama completo). Como siempre, te invitamos a revisa nuestras aplicaciones, regístrate y compruebe nuestra precisión con sus datos.
Cuando tiene que seleccionar el software de reconocimiento de voz/ASR, hay otros factores que van más allá de la precisión del reconocimiento lista para usar. Estos factores son, por ejemplo:
1. Haga clic aquí para obtener instrucciones sobre cómo acceder a nuestro sitio de demostración en vivo.
2. Si estás creando una aplicación de voz genial y quieres probar nuestras API, haz clic aquí para crear una cuenta de desarrollador y recibir 50$ en créditos gratis
3. Si quieres usar Voicegain como tu propio asistente de transcripción con IA para las reuniones, haz clic aquí.

Estamos muy contentos de anunciar el lanzamiento de dos nuevas funciones con nuestra aplicación Voicegain Transcribe.
(i) Resumen impulsado por LLMs.
(ii) Inicio de sesión único (actualmente disponible solo para clientes de Voicegain Edge/On-Prem)
El resumen de una transcripción es extremadamente valioso para varios tipos de contenido de audio. Ya sea que un usuario esté transcribiendo una reunión de negocios, una conferencia en el aula, un podcast o un evento web, revisar solo el resumen de la transcripción supone un gran ahorro de tiempo en comparación con tener que leer la transcripción completa. Con esta versión, todas las transcripciones generadas por Voicegain Transcribe se resumirán con precisión utilizando potentes y vanguardistas LLM.
Además del resumen de la transcripción, Voicegain también admite la extracción de elementos clave como acciones, problemas, riesgos y dependencias.
Para los usuarios de Voicegain Transcribe Cloud, el resumen funciona con ChatGPT (GPT 3.5 Turbo APIs). Básicamente, enviamos la transcripción de la reunión a ChatGPT y le pedimos que resuma la reunión. Mostramos y almacenamos el resumen devuelto en Voicegain Transcribe.
Para los usuarios de Voicegain Transcribe Edge/On-Prem, ofrecemos un modelo de LLM de código abierto que se ha ajustado con precisión a los datos de las reuniones. Este modelo de LLM perfeccionado se implementa junto con toda la plataforma Voicegain detrás del firewall del cliente (ya sea en una nube privada o en un centro de datos).
Con esta nueva versión, Voicegain Transcribe también admite la función SSO mediante el protocolo OIDC. Las soluciones de software de gestión de identidades más populares, como Okta, Ping Identity, Microsoft, Oracle, RSA, etc., son compatibles con el protocolo OIDC.
Actualmente, esta función solo está disponible para los clientes de Voicegain Edge/On-Prem y también estará disponible muy pronto para los clientes de Voicegain Cloud.
Voicegain Transcribe es una plataforma de inteligencia artificial para reuniones que prioriza la privacidad y que se puede implementar «completamente detrás» del firewall de una empresa o negocio. También se puede acceder a ella como servicio en la nube.
Por inscribiéndose hoy, se suscribirá a nuestro plan gratuito para siempre, lo que lo convierte en elegible para recibir 120 minutos de transcripción de reuniones gratis cada mes. Una vez que esté satisfecho con nuestra precisión y nuestra experiencia de usuario, podrá cambiarse fácilmente a planes de pago o ponerse en contacto con nosotros para conocer las opciones de nube privada virtual o local.
Si tiene alguna pregunta, envíenos un correo electrónico a support@voicegain.ai

¡Los LLM como ChatGPT y Bard están arrasando en el mundo! Un LLM como ChatGPT es muy bueno tanto para entender el lenguaje como para adquirir conocimientos sobre este contenido. El resultado de esto es casi espeluznante y aterrador. Porque una vez que estos LLM adquieren conocimientos, pueden responder con mucha precisión a preguntas que en el pasado parecían requerir el juicio humano.
Un gran caso de uso de los LLM es el análisis de las reuniones de negocios, tanto internas (entre empleados) como externas (por ejemplo, conversaciones con clientes, proveedores, etc.).

En los últimos años, las empresas han estado utilizando principalmente ofertas de SaaS de inteligencia de ventas e ingresos para múltiples inquilinos y para reuniones con IA para transcribir las conversaciones comerciales y extraer información. Con estas ofertas para varios usuarios, la transcripción y el procesamiento del lenguaje natural se llevan a cabo en la nube de Vendor. Una vez que se genera la transcripción, se utilizan los modelos de NLU ofrecidos por el proveedor de Meeting AI para extraer información. Por ejemplo, los productos de inteligencia de ingresos, como Gong, extraen preguntas y bloquean las ventas en las conversaciones de ventas. La mayoría de los asistentes de inteligencia artificial para reuniones extraen resúmenes y elementos de acción.
Básicamente, estos modelos de NLU, y muchos de ellos son anteriores a los LLM, podían resumir y extraer temas, palabras clave y frases. A las empresas no les importaba utilizar la infraestructura en la nube del proveedor para almacenar las transcripciones, ya que lo que podía hacer esta NLU parecía bastante inofensivo.
Sin embargo, los LLM llevan esto a un nivel completamente diferente. Nuestro equipo utilizó la API Open AI Embeddings para generar incrustaciones de las transcripciones de nuestras reuniones diarias que se realizaron durante un período de un mes. Almacenamos estas incrustaciones en una base de datos vectorial de código abierto (nuestra base de conocimientos). Durante las pruebas, para cada pregunta del usuario, generamos una incrustación de la pregunta y consultamos la base de datos vectorial (es decir, la base de conocimientos) para obtener incrustaciones relacionadas o similares.
Luego, proporcionamos estos documentos relacionados como contexto y la pregunta del usuario como mensaje a la API GPT 3.5 para que pudiera generar la respuesta. Obtuvimos unos resultados realmente buenos.
Pudimos obtener respuestas a las siguientes preguntas
1. Proporcione un resumen del contrato con<Largest Customer Name>.
2. ¿En qué se avanza<Key Initiative>?
3. ¿La empresa contrató nuevos empleados?
4. ¿La empresa habló de algún secreto comercial?
5. ¿Qué opina el equipo sobre Mongodb Atlas frente a Google Firestore?
6. ¿Qué nuevos productos planea desarrollar la Compañía?
7. ¿Qué proveedor de nube utiliza la empresa?
8. ¿Cuál es el progreso de una iniciativa clave?
9. ¿Los empleados están contentos trabajando en la empresa?
10. ¿El equipo está apagando incendios?
Las respuestas de ChatGPT a las preguntas anteriores fueron asombrosamente precisas e inquietantemente precisas. En cuanto a la pregunta 4, indicó que no quería responderla. Y cuando no disponía de la información adecuada (por ejemplo, la pregunta 9), sí lo indicó en su respuesta.
En Voicegain, siempre hemos sido grandes defensores de por qué la IA de voz debe permanecer al límite. Teníamos escrito sobre ello en el pasado.
Las transcripciones de las reuniones en cualquier negocio son una verdadera mina de oro de información. Ahora, con el poder de los LLM, ahora se pueden consultar con mucha facilidad para obtener información sorprendente. Sin embargo, si estas transcripciones se almacenan en la nube de otro proveedor, es posible que la información confidencial y exclusiva de cualquier empresa quede expuesta a terceros.
Por lo tanto, para las empresas es extremadamente importante que dichas transcripciones se almacenen solo en una infraestructura privada (detrás del firewall). Es muy importante que la TI empresarial se asegure de que esto suceda para proteger la información confidencial y de propiedad exclusiva.
Si está buscando una solución de este tipo, podemos ayudarlo. En Voicegain, ofrecemos Voicegain Transcribe, una solución empresarial para la IA de reuniones. Con Voicegain Transcribe, toda la solución se puede implementar en un centro de datos (sin sistema operativo) o en una nube privada. Puedes leer más sobre esto aquí.

El 1 de marzo de 2023, Open AI anunció que los desarrolladores podían acceder al modelo Open AI Whisper Speech-to-Text a través de API REST fáciles de usar. OpenAI también lanzó las API para GPT3.5, el LLM detrás del popular producto ChatGPT. Se espera que la próxima versión de LLM, GPT 4, esté disponible para el público en julio de 2023.
Desde el lanzamiento inicial de Open AI Whisper en octubre de 2022, ha sido un gran atractivo para los desarrolladores. Un ASR de código abierto de alta precisión es extremadamente atractivo. El Whisper de OpenAI ha sido entrenado con 680 000 horas de datos de audio, mucho más de lo que utilizan la mayoría de los modelos. Aquí hay un enlace a sus github.
Sin embargo, la comunidad de desarrolladores que busca aprovechar Whisper se enfrenta a tres limitaciones principales:
1. Costos de infraestructura: La ejecución de Whisper, especialmente los modelos grandes y medianos, requiere costosas opciones de procesamiento basadas en GPU que consumen mucha memoria (consulte a continuación).
2. Experiencia interna en IA: Para utilizar el modelo Whisper de Open AI, una empresa tiene que invertir en la creación de un equipo interno de ingeniería de aprendizaje automático que sea capaz de operar, optimizar y dar soporte a Whisper en un entorno de producción. Si bien Whisper ofrece funciones básicas, como la conversión de voz a texto, la identificación del idioma, la puntuación y el formato, aún faltan algunas funciones de inteligencia artificial, como la diarización de los hablantes y la redacción de información personal identificable, que habría que desarrollar. Además, las empresas deberían establecer un NOC en tiempo real para ofrecer un soporte continuo. Incluso contratar y mantener un equipo de desarrolladores a pequeña escala de 2 a 3 personas podría resultar caro, a menos que el volumen de llamadas justifique dicha inversión. Este equipo interno también debe asumir la plena responsabilidad de las tareas relacionadas con la infraestructura de la nube, como el escalado automático y la supervisión de registros, para garantizar el tiempo de actividad.
3. Falta de soporte para tiempo real: Whisper es un modelo de conversión de voz a texto por lotes. Los desarrolladores que necesitan modelos de transmisión de voz a texto deben evaluar otras opciones de ASR/STT.
Al asumir ahora la responsabilidad de alojar este modelo y hacerlo accesible a través de API fáciles de usar, tanto Open AI como Voicegain abordan las dos primeras limitaciones.
Actualización de agosto de 2023: El 5 de agosto de 2023, Voicegain anunció el lanzamiento de Voicegain Whisper, una versión optimizada de Whisper de Open AI que utiliza las API de Voicegain. He aquí un eslabón al anuncio. Además de Voicegain Whisper, Voicegain también ofrece transmisión de voz a texto en tiempo real y en streaming y otras funciones, como la compatibilidad con dos canales y estéreo (necesaria para los centros de llamadas), la diarización de los altavoces y la redacción de información personal identificable. Todo esto se ofrece en la infraestructura compatible con las normas PCI y SOC-2 de Voicegain.
En este artículo se destacan algunos de los puntos fuertes y las limitaciones clave del uso de Whisper, ya sea que utilices las API de Open AI, las API de Voicegain o si lo alojas por tu cuenta.
En nuestras pruebas comparativas, los modelos Whisper de OpenAI demostraron una alta precisión para una amplia gama de conjuntos de datos de audio. Nuestros ingenieros de aprendizaje automático concluyeron que los modelos Whisper funcionan bien en conjuntos de datos de audio que van desde reuniones, podcasts, conferencias en el aula, vídeos de YouTube y audio para centros de llamadas. Comparamos Whisper-base, Whisper-small y Whisper-Medium con algunos de los mejores motores de ASR/conversión de voz a texto del mercado.
La tasa media de errores de palabras (WER) de Whisper-medium fue del 11,46% para el audio de las reuniones y del 17,7% para el audio de los centros de llamadas. De hecho, esta cifra fue inferior a la de otras grandes empresas, como Microsoft Azure y Google, que ofrecían los WER de STT. Descubrimos que AWS Transcribe tenía un WER que competía con el de Whisper.
He aquí una observación interesante - es posible superar la precisión de reconocimiento de Whisper, sin embargo, sería necesario crear modelos personalizados. Los modelos personalizados son modelos que se entrenan con los datos de audio específicos de nuestros clientes. De hecho, en el caso del audio para centros de llamadas, nuestros ingenieros de aprendizaje automático pudieron demostrar que nuestros modelos de conversión de voz a texto específicos para centros de llamadas eran iguales o incluso mejores que algunos de los modelos de Whisper. Esto tiene sentido desde el punto de vista intuitivo, ya que Open AI no puede acceder fácilmente al audio de los centros de llamadas en Internet.
Póngase en contacto con nosotros por correo electrónico (support@voicegain.ai) si desea revisar y validar/probar estos puntos de referencia de precisión.
El precio de Whisper, de 0,006 USD por minuto (0,36 USD por hora), es mucho más bajo que el de las ofertas de conversión de voz a texto de algunos de los otros grandes actores de la nube. Esto se traduce en un descuento del 75% en Google Speech-to-Text y AWS Transcribe (según los precios a la fecha de esta publicación).
Actualización de agosto de 2023: En el lanzamiento de Voicegain Whisper, Voicegain anunció un precio de lista de 0,0037 USD por minuto (0,225 USD por hora). Este precio es un 37,5% más bajo que el precio de Open AI y se ha conseguido desde que optimizamos el rendimiento de Whisper. Para probarlo, regístrate para obtener una cuenta de desarrollador gratuita. Se proporcionan instrucciones aquí.
Lo que también fue significativo fue que Open AI anunció el lanzamiento de las API de ChatGPT con el lanzamiento de las API de Whisper. Los desarrolladores pueden combinar la potencia de los modelos Whisper Speech-to-Text con los modelos GPT 3.5 y GPT 4.0 LLM (el modelo subyacente que utiliza ChatGPT) para impulsar aplicaciones de IA conversacional muy interesantes. Sin embargo, hay una consideración importante: el uso de la API Whisper con LLM como ChatGPT funciona siempre que la aplicación solo utilice audio pregrabado o por lotes (por ejemplo, analizar la grabación de las conversaciones del centro de llamadas para garantizar el control de calidad o el cumplimiento o transcribir y extraer las reuniones de Zoom para recordar el contexto). Los desarrolladores que buscan crear bots de voz o IVR de voz necesitan un buen modelo de conversión de voz a texto en tiempo real.
Como se indicó anteriormente, Whisper de Open AI no admite aplicaciones que requieran transcripciones en tiempo real o en streaming; esto podría ser relevante para una amplia variedad de aplicaciones de IA que se centran en casos de uso de centros de llamadas, educativos, legales y de reuniones. Si estás buscando un proveedor de API de transmisión de voz a texto, no dudes en ponerte en contacto con nosotros a través de la dirección de correo electrónico que se indica a continuación
El rendimiento de los modelos Whisper, tanto para los modelos medianos como para los grandes, es relativamente bajo. En Voicegain, nuestros ingenieros de aprendizaje automático han probado el rendimiento de los modelos Whisper en varias instancias informáticas populares basadas en GPU de NVIDIA disponibles en nubes públicas (AWS, GCP, Microsoft Azure y Oracle Cloud). También tenemos experiencia real porque procesamos más de 10 millones de horas de audio al año. Como resultado, tenemos una sólida comprensión de lo que se necesita para ejecutar un modelo como Whisper de OpenAI en un entorno de producción.
Hemos descubierto que el coste de infraestructura de ejecutar Whisper-Medium en la nube el entorno está en el rango de 0,07 a 0,10 dólares/hora. Puede ponerse en contacto con nosotros por correo electrónico para obtener las suposiciones detalladas y el respaldo de nuestro modelo de costos. Un factor importante a tener en cuenta es que, en un entorno de producción de un solo inquilino, la infraestructura informática no puede ejecutarse con un uso muy alto. El rendimiento máximo requerido para soportar el tráfico real puede ser varias veces mayor (2 a 3 veces) que el rendimiento promedio. Net-net, determinamos que, si bien los desarrolladores no tendrían que pagar por las licencias de software, los costos de la infraestructura de la nube seguirían siendo sustanciales.
Además de este coste de infraestructura, el mayor gasto de ejecutar Whisper on the Edge (local o nube privada) es que se necesitaría un equipo dedicado de ingeniería y desarrollo de back-end que pudiera dividir la grabación de audio en segmentos que se pudieran enviar a Whisper y gestionar las colas. Este equipo también tendría que supervisar todas las necesidades de seguridad de la información y cumplimiento (por ejemplo, realizar análisis de vulnerabilidades, detectar intrusos, etc.).
A la fecha de publicación de este post, Whisper no cuenta con una API de audio multicanal. Por lo tanto, si tu aplicación incluye audio con varios altavoces, el precio por minuto efectivo de Whisper es igual al número de canales * 0,006. Tanto para reuniones como para centros de llamadas, este precio puede resultar prohibitivo.
A esta versión de Whisper le faltan algunas funciones clave que los desarrolladores necesitarían. Las tres características importantes que hemos observado son la diarización (separación de los altavoces), las marcas de tiempo y la redacción de información personal.
Voicegain está trabajando para lanzar un modelo Voicegain-Whisper a través de sus API. De este modo, los desarrolladores pueden aprovechar las ventajas de una infraestructura compatible con el protocolo PCI/SOC-2 de Voicegain y de funciones avanzadas, como la creación de diarios, la redacción de información de identificación personal, el cumplimiento de las normas PCI y las marcas de tiempo. Para unirse a la lista de espera, envíenos un correo electrónico a sales@voicegain.ai
En Voicegain, creamos modelos de voz a texto/ASR basados en el aprendizaje profundo que igualan o superan la precisión de los modelos STT de los grandes actores. Durante más de 4 años, los clientes emergentes y empresariales han utilizado nuestras API para crear y lanzar productos exitosos que procesan más de 600 millones de minutos al año. Nos centramos en los desarrolladores que necesitan una alta precisión (que se logra mediante el entrenamiento de modelos acústicos personalizados) y la implementación en infraestructuras privadas a un precio asequible. Ofrecemos un acuerdo de nivel de servicio preciso en el que garantizamos que un modelo personalizado que se base en tus datos será tan preciso, si no más, que las opciones más populares, como Whisper de Open AI.
También tenemos modelos que están capacitados específicamente en audio para centros de llamadas. Si bien Whisper es un competidor digno (por supuesto, una empresa mucho más grande con 100 veces más recursos que nosotros), como desarrolladores acogemos con satisfacción la innovación que Open AI está liberando en este mercado. Al añadir las API de ChatGPT a nuestra conversión de voz a texto, tenemos previsto ampliar nuestra oferta de API a la comunidad de desarrolladores.
Para crear una cuenta de desarrollador en Voicegain con créditos gratuitos, haz clic aquí.

Al igual que Voicegain Transcribe, existen otras soluciones de inteligencia artificial para reuniones y toma de notas basadas en la nube que funcionan con plataformas de videoconferencias como Zoom y Microsoft Teams. Sin embargo, no cumplen con los requisitos de los clientes empresariales sensibles a la privacidad en los sectores de los servicios financieros, la atención médica, la fabricación y la alta tecnología y otros sectores industriales. Los problemas de privacidad y control de los datos harían que estos clientes desearan implementar un asistente de reuniones basado en inteligencia artificial en su infraestructura privada, detrás de su firewall corporativo.
Voicegain Transcribe se ha diseñado y desarrollado para el caso de uso de centros de datos locales o nubes privadas virtuales. Voicegain ya lo ha implementado en una gran empresa mundial que figura en la lista Fortune 50, lo que lo convierte en una de las primeras soluciones de asistente de reuniones con inteligencia artificial que funcionan realmente en las instalaciones y en la nube privada del mercado.
Las principales características de Voicegain Transcribe son:
Las grabaciones locales de Zoom son grabaciones de sus reuniones que se guardan en el disco duro de su ordenador en su sistema de archivos y no en la nube de Zoom. Esta función garantiza que el contenido de audio y vídeo grabado, confidencial y sensible a la privacidad, se almacene en la empresa y Zoom no pueda acceder a él.
Voicegain ofrece una aplicación de escritorio para Windows (la aplicación para Mac OS está en la hoja de ruta) que accede a estas grabaciones de Zoom y las envía para su transcripción y NLU.
La otra gran ventaja de Zoom Local Recordings es que Zoom admite la grabación de una pista de audio independiente para cada participante. Esta función aún no está disponible en su grabación en la nube (a partir de febrero de 2023). De este modo, Voicegain Transcribe with Zoom Local Recordings puede asignar etiquetas a los altavoces con una precisión del 100%.
Hay proveedores que ofrecen asistentes de reuniones que se unen desde la nube y graban. Sin embargo, cuando se elige esta solución, el asistente de reuniones solo tiene acceso a un archivo de audio mono combinado o fusionado que incluye el audio de todos los participantes. Por lo tanto, la solución Meeting AI tiene que «diarizar» el audio de la reunión, lo cual es un problema intrínsecamente difícil de resolver. Incluso los modelos más modernos de diarización y separación de altavoces solo tienen una precisión del 83 al 85%.
Para que cualquier solución de Meeting AI extraiga información significativa, la precisión de la transcripción subyacente es extremadamente importante. Si la conversión de voz a texto no es precisa, ni siquiera el mejor algoritmo de NLU o el modelo lingüístico más amplio pueden ofrecer análisis valiosos y precisos.
Voicegain puede entrenar la conversión de voz a texto subyacente para que ayude a transcribir con precisión diferentes acentos, palabras específicas del cliente y el entorno acústico específico.
Voicegain se integra con las soluciones de SSO empresarial mediante SAML. Voicegain también se integra con los sistemas de correo electrónico internos para simplificar las tareas de administración de usuarios, como el registro, el restablecimiento de contraseñas y los cambios, adiciones y eliminaciones.
Todo el audio, las transcripciones y los análisis basados en NLU de las reuniones se almacenan en bases de datos NoSQL y SQL controladas por la empresa. Las empresas pueden utilizar personal interno para mantener o administrar estas bases de datos y almacenamiento, o también pueden utilizar una opción de base de datos gestionada, como MongoDB Atlas, o Managed PostgreSQL de un proveedor de nube como Azure, AWS o GCP
Si está buscando una solución de IA para reuniones que pueda implementarse completamente detrás de su firewall corporativo o en su propia infraestructura de nube privada, Voicegain Transcribe es la solución perfecta para sus necesidades.
¿Tiene preguntas? Nos encantaría saber de ti. Envíanos un correo electrónico a -sales@voicegain.ai o support@voicegain.ai y estaremos encantados de ofrecerte más detalles.
.jpg)
Estamos muy contentos de anunciar el lanzamiento de Zoom Meeting Assistant para grabaciones locales. Está disponible de inmediato para todos los usuarios de Voicegain Transcribe que tengan un dispositivo Windows. El Zoom Meeting Assistant se puede instalar en ordenadores que tengan Windows 10 o Windows 11 como sistema operativo.
¿Qué son las grabaciones locales? Zoom ofrece dos formas de grabar una reunión: 1) Grabación en la nube: los usuarios de Zoom pueden guardar la grabación de la reunión en la nube de Zoom. 2) Grabación local: la grabación de la reunión se guarda localmente en el ordenador del usuario de Zoom. Estas grabaciones se guardan en la carpeta Zoom predeterminada del sistema de archivos. Zoom procesa la grabación y la pone a disposición en esta carpeta unos minutos después de que finalice la reunión.
A continuación se muestra una captura de pantalla de cómo un usuario de Zoom puede iniciar una grabación local.

Hay cuatro grandes beneficios de usar grabaciones locales
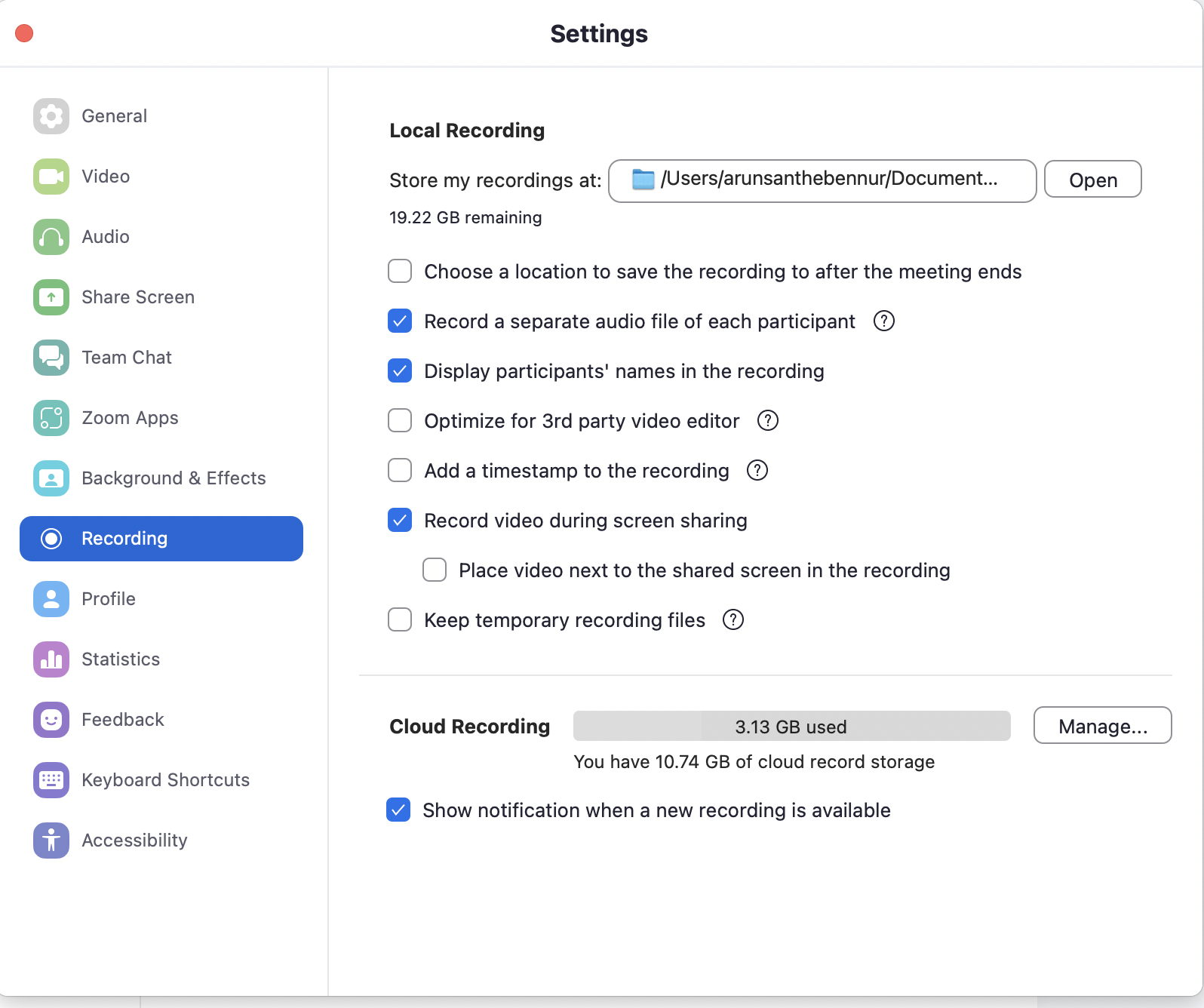
Para usar Voicegain Zoom Meeting Assistant, solo hay dos requisitos
1. Los usuarios primero deben registrarse para obtener una cuenta de Voicegain Transcribe. Voicegain ofrece un plan gratuito para siempre (hasta 2 horas de transcripción al mes) y los usuarios pueden registrarse con él eslabón. Puede obtener más información sobre Voicegain Transcribe aquí.
2. Deberían tener una computadora con Windows 10 u 11 como sistema operativo.
Esta aplicación para Windows se puede descargar desde la página «Aplicaciones» de Voicegain Transcribe. Una vez instalada la aplicación, los usuarios podrán acceder a ella desde la barra de tareas (o bandeja) de Windows. Todo lo que tienen que hacer es iniciar sesión en la aplicación Voicegain Transcribe desde el Meeting Assistant introduciendo su nombre de usuario y contraseña de Transcribe.
Una vez que la aplicación Meeting Assistant inicia sesión en Voicegain Transcribe, hace dos cosas
1. Escanea constantemente la carpeta Zoom en busca de nuevas grabaciones locales de las reuniones. En cuanto encuentra una grabación de este tipo, la envía o sube a Voicegain Transcribe para transcribir, resumir y extraer los elementos clave (acciones, problemas, bloqueos de ventas, preguntas, riesgos, etc.)
2. También puede unirse a cualquier reunión de Zoom como asistente de IA del usuario. Además, esta función funciona tanto si el usuario es el anfitrión de la reunión de Zoom como si solo es un participante. Al unirse a la reunión, el asistente de la reunión puede recopilar información sobre todos los participantes de la reunión.
Si bien la aplicación Meeting Assistant actual solo funciona para usuarios de Windows, Voicegain tiene aplicaciones nativas para Mac, Android y iPhone como parte de su hoja de ruta de productos.
Envíenos un correo electrónico a support@voicegain.ai si tiene alguna pregunta.

Han pasado otros 6 meses desde que publicamos nuestra última precisión de reconocimiento de voz punto de referencia. En aquel entonces, los resultados eran los siguientes (del más preciso al menos preciso): Microsoft, luego Amazon, seguido de cerca por Voicegain, luego el nuevo Google latest_long y el último Google Enhanced.
Si bien el pedido se ha mantenido igual al del último punto de referencia, tres empresas (Amazon, Voicegain y Microsoft) mostraron una mejora significativa.
Desde el último punto de referencia, en Voicegain hemos invertido en más formación, principalmente en conferencias, impartidas a través de zoom y en directo. La formación con este tipo de datos se tradujo en un aumento adicional de la precisión de nuestro modelo. De hecho, estamos en medio de una nueva ronda de formación centrada en las conversaciones en los centros de llamadas.
En lo que respecta a los demás reconocedores:
Hemos repetido la prueba con una metodología similar a la anterior: utilizamos 44 archivos del Conjunto de datos de Jason Kincaid y 20 archivos publicado por rev.ai y eliminó todos los archivos en los que ninguno de los reconocedores podía alcanzar una tasa de errores de palabras (WER) inferior al 25%.
Esta vez, solo un archivo fue tan difícil. Fue una entrevista telefónica de mala calidad (Entrevista a Byron Smith (111416 - YouTube) con un WER del 25,48%
Publicamos esto porque queremos asegurarnos de que cualquier tercero (cualquier proveedor, desarrollador o analista de ASR) pueda reproducir estos resultados.
Puedes ver diagramas de caja con los resultados de arriba. El gráfico también muestra la tasa de errores de palabras (WER) promedio y mediana
Solo 3 reconocedores han mejorado en los últimos 6 meses.
Los datos detallados de este punto de referencia indican que Amazon es mejor que Voicegain en los archivos de audio con un WER por debajo de la mediana y peor en los archivos de audio con una precisión por encima de la mediana. Por lo demás, AWS y Voicegain tienen una similitud muy similar. Sin embargo, también hemos realizado un análisis de rendimiento específico para cada cliente en el que ha sido al revés: Amazon es ligeramente mejor en los archivos de audio con un WER por encima de la media que en Voicegain, pero Voicegain es mejor en los archivos de audio con un WER por debajo de la media. En realidad, depende del tipo de archivos de audio, pero en general, nuestros resultados indican que Voicegain se parece mucho a AWS.
Veamos la cantidad de archivos en los que cada reconocedor era el mejor.
Ya hemos realizado el mismo punto de referencia 5 veces para poder dibujar gráficos que muestren cómo ha mejorado cada uno de los reconocedores en los últimos 2 años y 3 meses. (Ten en cuenta que los dos últimos resultados de Google provienen del modelo más reciente, mientras que otros resultados de Google provienen de vídeos mejorados).
Puedes ver claramente que Voicegain y Amazon empezaron bastante por detrás de Google y Microsoft, pero desde entonces se han puesto al día.
Google parece tener los ciclos de desarrollo más largos, con muy pocas mejoras desde septiembre de 2021 hasta hace aproximadamente medio año. Microsoft, por otro lado, lanza un reconocedor mejorado cada 6 meses. Nuestras versiones mejoradas son incluso más frecuentes que eso.


Como puede ver, el campo está muy cerca y se obtienen resultados diferentes en diferentes archivos (el promedio y la mediana no muestran el panorama completo). Como siempre, te invitamos a revisa nuestras aplicaciones, regístrate y compruebe nuestra precisión con sus datos.
Cuando tiene que seleccionar el software de reconocimiento de voz/ASR, hay otros factores que van más allá de la precisión del reconocimiento lista para usar. Estos factores son, por ejemplo:
1. Haga clic aquí para obtener instrucciones sobre cómo acceder a nuestro sitio de demostración en vivo.
2. Si estás creando una aplicación de voz genial y quieres probar nuestras API, haz clic aquí para crear una cuenta de desarrollador y recibir 50$ en créditos gratis
3. Si quieres usar Voicegain como tu propio asistente de transcripción con IA para las reuniones, haz clic aquí.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →¿Está interesado en personalizar el ASR o implementar Voicegain en su infraestructura?

Voicegain ayuda a los desarrolladores a crear increíbles aplicaciones compatibles con la voz al proporcionarles la plataforma de conversión de voz a texto más precisa, asequible y accesible.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices