
DALLAS, June 9, 2026 /PRNewswire-PRWeb/ -- Voicegain, a leading provider of AI-powered voice solutions for healthcare payers and contact centers, today announced the appointment of Tracy Puleo as Vice President of Sales.
In this role, Tracy will lead Voicegain's sales strategy, revenue growth initiatives, and customer acquisition efforts as the company rapidly scales its presence among health plans – Commercial, Medicaid and MA, third-party administrators (TPAs), and healthcare organizations seeking to transform member and provider experiences through generative Voice AI.
Tracy will lead sales for Voicegain Casey, a healthcare payer-focused software suite of three products that span the entire caller journey. They are (1) Conversational AI Voice Agents (2) Real-time Agent Assist (AI Co-Pilot) and (3) AI-Powered QA and Coaching Automation and Voice-of-Customer analytics. With the Voicegain Casey suite, healthcare organizations can elevate the member experience while lowering the operating costs of call centers.
Voicegain has rapidly emerged as a trusted AI partner for healthcare payer organizations with Voicegain Casey being used by over a dozen companies including Alliance Health, Samaritan Health, UnitedAg and Cottingham Buttler. Casey enables these organizations to augment their call center staff with real-time AI powered guidance and to automate routine member and provider inquiries like claims, eligibility and prior authorization status. Casey also analyzes 100% of all voice customer interactions and generates an automated QA score, extracts caller sentiment, CSAT and other Gen AI powered insights.
Voicegain Casey is built on the Voicegain platform, a leading privacy-first Voice AI platform that transcribes over 3 Billion minutes of audio for leading enterprises and mid-market companies. It is HIPAA, PCI and SOC-2 compliant and supports PII redaction, speaker diarization and 99 languages.
"Tracy is a proven healthcare sales leader with a strong track record of building relationships, delivering results, and helping healthcare organizations solve complex challenges," said Arun Santhebennur, Co-Founder and CEO of Voicegain. "Health plans face significant pressures to maintain and improve their HEDIS/STAR ratings and lower their administrative costs. They are looking for practical and proven AI solutions that improve member experience, increase operational efficiency, and drive measurable outcomes. Tracy's expertise and leadership will be instrumental in helping us accelerate our growth and expand our impact across the healthcare industry."
Tracy brings extensive experience in healthcare technology, payer engagement, customer experience, and enterprise sales and has led Sales for organizations like Zipari, Vimly Benefits, and ClickBoarding. Throughout her career, she has successfully partnered with health plans and healthcare organizations to implement innovative software solutions that increase member satisfaction, enhance operational performance, and support organizational growth.
"I am excited to join Voicegain at such a pivotal time," said Tracy Puleo. "Healthcare organizations are under tremendous pressure to improve member experiences while controlling costs and increasing efficiency. Voicegain Casey addresses these challenges in a meaningful way, and I look forward to working with our customers and partners to help them realize the full value of AI-driven engagement."
As Vice President of Sales, Tracy will focus on expanding Voicegain's customer base with healthcare payers, strengthening strategic partnerships, and helping organizations leverage AI to improve outcomes for members, providers, and contact center teams.
About Voicegain
Voicegain is a healthcare focused Voice AI company that offers AI Voice Agents, Real-time Agent Assist, Voice-of-Customer based analytics and automated quality assurance solutions. These products are designed to improve contact center efficiency and performance and elevate the member experiences.
Media Contact
Arun Santhebennur
Co-founder & CEO, Voicegain
Email: Arun@voicegain.ai
Website: https://www.voicegain.ai
Media Contact
Arun Santhebennur, Voicegain, 1 9725180863 701, arun@voicegain.ai, https://www.voicegain.ai/conversational-ivr
SOURCE Voicegain

DALLAS, June 9, 2026 /PRNewswire-PRWeb/ -- Voicegain, a leading provider of AI-powered voice solutions for healthcare payers and contact centers, today announced the appointment of Tracy Puleo as Vice President of Sales.
In this role, Tracy will lead Voicegain's sales strategy, revenue growth initiatives, and customer acquisition efforts as the company rapidly scales its presence among health plans – Commercial, Medicaid and MA, third-party administrators (TPAs), and healthcare organizations seeking to transform member and provider experiences through generative Voice AI.
Tracy will lead sales for Voicegain Casey, a healthcare payer-focused software suite of three products that span the entire caller journey. They are (1) Conversational AI Voice Agents (2) Real-time Agent Assist (AI Co-Pilot) and (3) AI-Powered QA and Coaching Automation and Voice-of-Customer analytics. With the Voicegain Casey suite, healthcare organizations can elevate the member experience while lowering the operating costs of call centers.
Voicegain has rapidly emerged as a trusted AI partner for healthcare payer organizations with Voicegain Casey being used by over a dozen companies including Alliance Health, Samaritan Health, UnitedAg and Cottingham Buttler. Casey enables these organizations to augment their call center staff with real-time AI powered guidance and to automate routine member and provider inquiries like claims, eligibility and prior authorization status. Casey also analyzes 100% of all voice customer interactions and generates an automated QA score, extracts caller sentiment, CSAT and other Gen AI powered insights.
Voicegain Casey is built on the Voicegain platform, a leading privacy-first Voice AI platform that transcribes over 3 Billion minutes of audio for leading enterprises and mid-market companies. It is HIPAA, PCI and SOC-2 compliant and supports PII redaction, speaker diarization and 99 languages.
"Tracy is a proven healthcare sales leader with a strong track record of building relationships, delivering results, and helping healthcare organizations solve complex challenges," said Arun Santhebennur, Co-Founder and CEO of Voicegain. "Health plans face significant pressures to maintain and improve their HEDIS/STAR ratings and lower their administrative costs. They are looking for practical and proven AI solutions that improve member experience, increase operational efficiency, and drive measurable outcomes. Tracy's expertise and leadership will be instrumental in helping us accelerate our growth and expand our impact across the healthcare industry."
Tracy brings extensive experience in healthcare technology, payer engagement, customer experience, and enterprise sales and has led Sales for organizations like Zipari, Vimly Benefits, and ClickBoarding. Throughout her career, she has successfully partnered with health plans and healthcare organizations to implement innovative software solutions that increase member satisfaction, enhance operational performance, and support organizational growth.
"I am excited to join Voicegain at such a pivotal time," said Tracy Puleo. "Healthcare organizations are under tremendous pressure to improve member experiences while controlling costs and increasing efficiency. Voicegain Casey addresses these challenges in a meaningful way, and I look forward to working with our customers and partners to help them realize the full value of AI-driven engagement."
As Vice President of Sales, Tracy will focus on expanding Voicegain's customer base with healthcare payers, strengthening strategic partnerships, and helping organizations leverage AI to improve outcomes for members, providers, and contact center teams.
About Voicegain
Voicegain is a healthcare focused Voice AI company that offers AI Voice Agents, Real-time Agent Assist, Voice-of-Customer based analytics and automated quality assurance solutions. These products are designed to improve contact center efficiency and performance and elevate the member experiences.
Media Contact
Arun Santhebennur
Co-founder & CEO, Voicegain
Email: Arun@voicegain.ai
Website: https://www.voicegain.ai
Media Contact
Arun Santhebennur, Voicegain, 1 9725180863 701, arun@voicegain.ai, https://www.voicegain.ai/conversational-ivr
SOURCE Voicegain

New unified platform combines AI voice agent automation with Real-time agent assistance and Auto QA, enabling healthcare payers to reduce average handle time (AHT) and improve first contact resolution (FCR) in their call centers.
IRVING, Texas and SAN FRANCISCO, Jan. 7, 2026 /PRNewswire-PRWeb/ -- Voicegain, a leader in AI Voice Agents and Infrastructure, today announced the acquisition of TrampolineAI, a venture-backed healthcare payer-focused Contact Center AI company whose products supports thousands of member interactions. The acquisition unifies Voicegain's AI Voice Agent automation with Trampoline's real-time agent assistance and Auto QA capabilities, enabling healthcare payers to optimize their entire contact center operation—from fully automated interactions to AI-enhanced human agent support.
Healthcare payer contact centers face mounting pressure to reduce costs while improving member experience. The reasons vary from CMS pressure, Medicaid redeterminations, Medicare AEP volume and staffing shortages. The challenge lies in balancing automation for routine inquiries with personalized support for complex interactions. The combined Voicegain and TrampolineAI platform addresses this challenge by providing a comprehensive solution that spans the full spectrum of contact center needs—automating high-volume routine calls while empowering human agents with real-time intelligence for interactions that require specialized attention.
"We're seeing strong demand from healthcare payers for a production-ready Voice AI platform. TrampolineAI brings deep payer contact center expertise and deployments at scale, accelerating our mission at Voicegain." — Arun Santhebennur
Over the past two years, Voicegain has scaled Casey, an AI Voice Agent purpose-built for health plans, TPAs, utilization management, and other healthcare payer businesses. Casey answers and triages member and provider calls in health insurance payer call centers. After performing HIPAA validation, Casey automates routine caller intents related to claims, eligibility, coverage/benefits, and prior authorization. For calls requiring live assistance, Casey transfers the interaction context via screen pop to human agents.
TrampolineAI has developed a payer-focused Generative AI suite of contact center products—Assist, Analyze, and Auto QA—designed to enhance human agent efficiency and effectiveness. The platform analyzes conversations between members and agents in real-time, leveraging real-time transcription and Gen AI models. It provides real-time answers by scanning plan documents such as Summary of Benefits and Coverage (SBCs) and Summary Plan Descriptions (SPDs), fills agent checklists automatically, and generates payer-optimized interaction summaries. Since its founding, TrampolineAI has established deployments with leading TPAs and health plans, processing hundreds of thousands of member interactions.
"Our mission at Voicegain is to enable businesses to deploy private, mission-critical Voice AI at scale," said Arun Santhebennur, Co-founder and CEO of Voicegain. "As we enter 2026, we are seeing strong demand from healthcare payers for a comprehensive, production-ready Voice AI platform. The TrampolineAI team brings deep expertise in healthcare payer operations and contact center technology, and their solutions are already deployed at scale across multiple payer environments."
Through this acquisition, Voicegain expands the Casey platform with purpose-built capabilities for payer contact centers, including AI-assisted agent workflows, real-time sentiment analysis, and automated quality monitoring. TrampolineAI customers gain access to Voicegain's AI Voice Agents, enterprise-grade Voice AI infrastructure including real-time and batch transcription, and large-scale deployment capabilities, while continuing to receive uninterrupted service.
"We founded TrampolineAI to address the significant administrative cost challenges healthcare payers face by deploying Generative Voice AI in production environments at scale," said Mike Bourke, Founder and CEO of TrampolineAI. "Joining Voicegain allows us to accelerate that mission with their enterprise-grade infrastructure, engineering capabilities, and established customer base in the healthcare payer market. Together, we can deliver a truly comprehensive solution that serves the full range of contact center needs."
A TPA deploying TrampolineAI noted the platform's immediate impact, stating that the data and insights surfaced by the application were fantastic, allowing the organization to see trends and issues immediately across all incoming calls.
The combined platform positions Voicegain to deliver a complete contact center solution spanning IVA call automation, real-time transcription and agent assist, Medicare and Medicaid compliant automated QA, and next-generation analytics with native LLM analysis capabilities. Integration work is already in progress, and customers will begin seeing benefits of the combined platform in Q1 2026.
Following the acquisition, TrampolineAI founding team members Mike Bourke and Jason Fama have joined Voicegain's Advisory Board, where they will provide strategic guidance on product development and AI innovation for healthcare payer applications.
The terms of the acquisition were not disclosed.
About Voicegain
Voicegain offers healthcare payer-focused AI Voice Agents and a private Voice AI platform that enables enterprises to build, deploy, and scale voice-driven applications. Voicegain Casey is designed specifically for healthcare payers, supporting automated and assisted customer service interactions with enterprise-grade security, scalability, and compliance. For more information, visit voicegain.ai.
About TrampolineAI
TrampolineAI was a venture-backed voice AI company focused on healthcare payer solutions. The company applies Generative Voice AI to contact centers to improve operational efficiency, member experience, and compliance through real-time agent assist, sentiment analysis, and automated quality assurance technologies. For more information, visit trampolineai.com.
Media Contact:
Arun Santhebennur
Co-founder & CEO, Voicegain
Media Contact
Arun Santhebennur, Voicegain, 1 9725180863 701, arun@voicegain.ai, https://www.voicegain.ai
SOURCE Voicegain

This article highlights the technical challenges in redaction of PII, PCI and PHI information in call center recordings for compliance requirements. It is focused on CIOs, CISOs and VP Info-Secs of Enterprises and BPOs that are responsible for compliant recording and storage in their Call Centers. It is also relevant to Product and Engineering leaders of Voice AI software companies targeting the call center.
PII redaction is a major requirement in regulated industries like telecom, financial services, health care and government. These call routinely deal with a lot of Personally Identifiable Information (PII) and Personal Health Information (PHI). In addition if a call center is processing payments, it needs to adhere to standards of PCI-DSS.
Redaction of Call Center recordings involves 3 main steps, 1) Transcription 2) Named-Entity Recognition of PII/PHI/PCI entities and 3) Redaction (in both Audio & Text) of these entities. In order to be compliant with standards like PCI and HIPAA, it is important that before storing the audio data and text transcript long-term, all such PII information is masked in text and removed in audio prior to storage.
Most modern call center recordings are 2-channel or stereo. A simplistic algorithm designed for mono-channel recording will not work. For example, establishing that a credit card is being requested by the Agent can span multiple turns in the conversations. The NER algorithm while establishing context has to consider both channels. Also establishing where the context starts and ends is an important criterion.
In real-world conversations, customers are not very precise while sharing PII information. For example when they share their credit card number they can make mistakes while reading out the 15 or 16 digits. The Agent may not hear certain digits and ask the user to confirm or repeat certain digits. So when you are designing the algorithm to identify the PII entities it needs to be ablet to correct for all of this.
Transcription accuracy especially in telephone conversations, which encode the audio in 8kHz, may result in missed or additional digits. Having a simple rule related to digit length - say 15 for American Express and 16 for Visa will not work. Also sometimes digits may get recognized as words based on accents. For example "eight" may get recognized as "ate" if spoken with an accent.
As shared in the first point above, the problem becomes one of establishing a context window where the PII information is shared. In the first place, it needs to be long enough to even recognize that PII information is being requested. However extending the context window too much could start to introduce false positives. There may be other important numbers - for example say a tracking number or confirmation number that is also spoken not too far from the PII information.
Net-net designing an algorithm that is able to look across two channels for stereo recordings, account for speech recognition errors and perform accurate PII entity recognition over turns of a conversation with a well-balanced context window is the key to successful PII redaction.
We partnered with Sutherland Global, a Top 10 BPO, to build a compliant recording for their large install base of Fortune 500 companies. The Voicegain platform - which performs both transcription and PII compliant redaction- is deployed in their VPC. We tuned our algorithm over several months to get it to pass stringent test criteria.
Today our PII Redaction has achieved an accuracy of over 95%.
If you are looking to build a PII/PCI/PHI compliant recording solution, please give us a shout. We would love to share our experiences. Email us at sales@voicegain.ai

Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
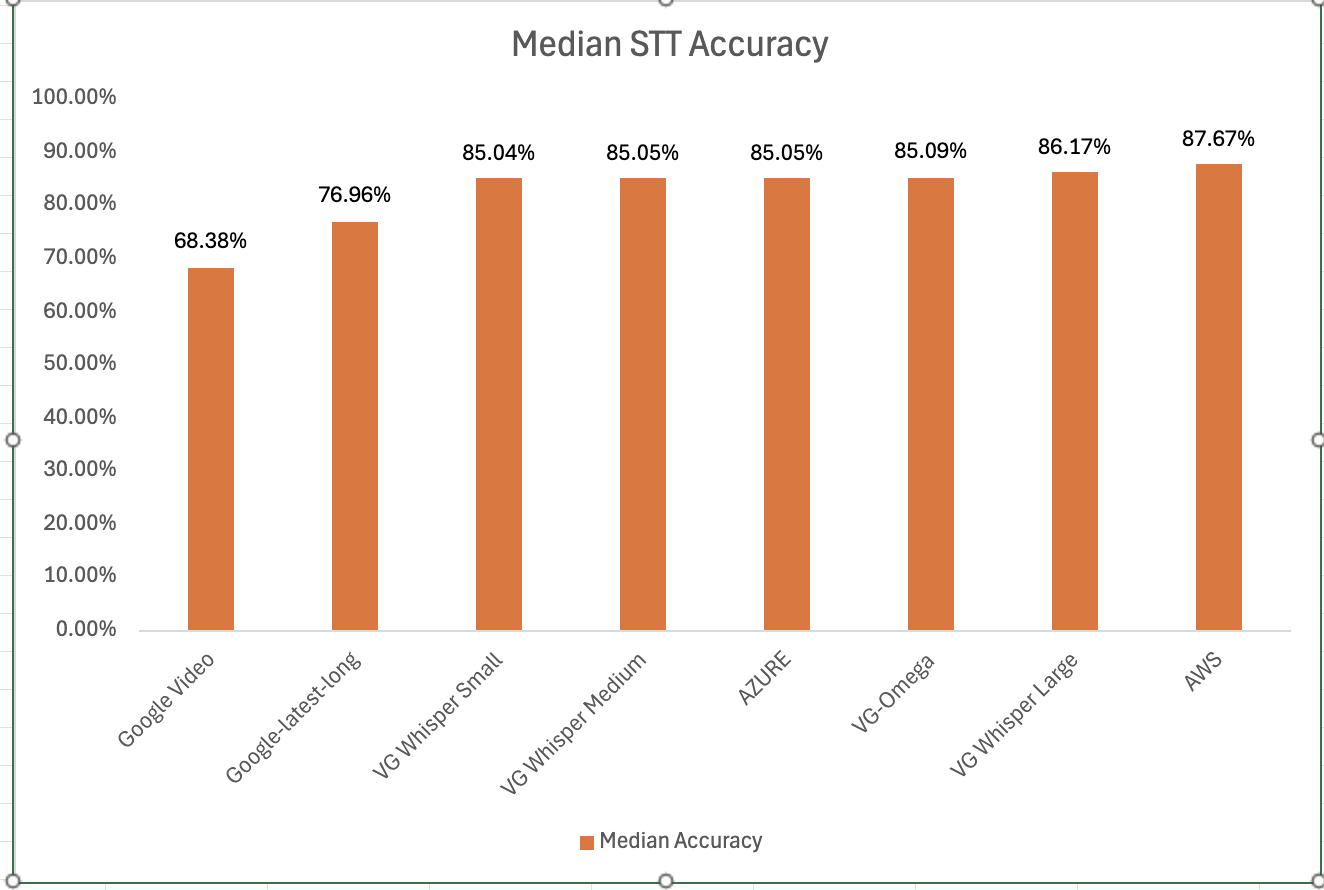
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.

This article is for companies building Voice AI Apps targeting the Contact Center. It outlines the key technical features, beyond accuracy, that are important while evaluating an OEM Speech-to-Text (STT) API. Usually, most analyses focus on the importance of accuracy and metrics like benchmarks of word error rates (WER). While accuracy is very important, there are other technical features that are equally important for contact center AI apps.
There are multiple use-cases for Voice AI Apps in the ContactCenter. Some of the common use cases are 1) AI Voicebot or Voice Agent 2) Real-time Agent Assist 3)Post Call Speech Analytics.
This article is focused on the third use-case which is Post-Call Speech Analytics. This use-case relies on batch STT APIs while the first two use-cases require streaming transcription. This Speech Analytics App helps the Quality Assurance and Agent-Performance management process. This article is intended for Product Managers and Engineering leads involved in building such AI Voice Apps that target the QA, Coaching and Agent Performance management process in the call center. Companies building such apps could include 1) CCaaS Vendors adding AI features, 2) Enterprise IT or Call Center BPO Digital organizations building an in-house Speech Analytics App 3) Call Center Voice AI Startups
Very often, call-center audio recordings are only available in mono. And even if the audio recording is in 2-channel/stereo, it could include multiple voices in a single channel. For example, the Agent channel can include IVR prompts and hold music recordings in addition to the Agent voice. Hence a very important criterion for an OEM Speech-to-Text vendor is that they provide accurate speaker diarization.
We would recommend doing a test of various speech-to-text vendors with a good sample set of mono audio files. Select files that are going to be used in production and calculate the Diarization Error Rate. Here is a useful link that outlines the technical aspects of understanding and measuring speaker diarization.
A very common requirement of Voice AI Apps is to redact PII – which stands for Personally Identifiable Information. PII Redaction is a post-processing step that a Speech-to-Text API vendor needs to perform. It involves accurate identification of entities like name, email address, phone number and mailing addresses and subsequent redaction both in text and audio. In addition, there are PCI – Payment Card Industry – specific named entities like Credit Card number, 3-digit PIN and expiry dates. Successful PII and PCI redaction requires post-processing algorithms to accurately identify a wide range of PII entities and cover a wide range of test scenarios. These test scenarios need to cover scenarios where there errors in user input and errors in speech recognition too.
There is another important capability related to PCI/PII redaction. Very often PII/PCI entities are present across multiple turns in a conversation between an Agent and Caller. It is important that the post-processing algorithm of the OEM Speech-to-Text vendor is able to process both channels simultaneously when looking for these named entities.
A Call Center audio recording could start off in one languageand then switch to another. The Speech-to-Text API should be able to detect language and then perform the transcription.
There will always be words that are not accurately transcribed by even the most accurate Speech-to-Text model. The API should include support for Hints or Keyword Boosting where words that are consistently misrecognized can get replaced by the correctly transcribed word. This is especially applicable for names of companies, products and industry specific terminology.
There are AI models that measure sentiment and emotion, and these models can be incorporated in the post-processing stage of transcription to enhance the Speech-to-Text API. Sentiment is extracted from the text of the transcript while Emotion is computed from the tone of the audio. A well-designed API should return Sentiment and Emotion throughout the interaction between the Agent and Caller. It should effectively compute the overall sentiment of the call by weighting the “ending sentiment” appropriately.
While measuring the quality of an Agent-Caller conversation, there are a few important audio-related metrics that are tracked in a call center. These include Talk-Listen Ratios, overtalk incidents and excessive silence and hold.
There are other LLM-powered features like computation of theQA Score and the summary of the conversation. However, these are features are builtby the developer of the AI Voice App by integrating the output of the Speech-to-TextAPI with the APIs offered by the LLM of the developer’s choice.

This Article provides an overview of how AI Voice Agents can lower call center operating costs and also simultaneously elevate the brand perception and customer service reputation of the health plan or the TPA. These AI Voice Agents can automate routine inquiries like Claim Status, Eligibility Verification and Benefits Inquiries.
Health Plans and TPAs face intense pressure to lower operating costs. There are several reasons 1) Medicare (& Medicare Advantage) and Medicaid reimbursement rates are going down. 2) Commercial Groups are pushing back on decades of price increases. 3) Lucrative revenue sources like pharmacy rebates are drying up.
There is also an urgent need to elevate the member experience and improve the Net Promoter Score (NPS) . Newer products like level-funded, direct primary care and ICHRAs are directly competing with Health plans and TPAs and member experience is increasingly the source of competitive advantage.
A modern LLM-Powered AI Voice Agent can transform the call center experience. It can answer all the calls received at the call center - whether they are from members or providers. Callers can speak in full sentences with the AI Voice Agent and describe the reason for their call in their own language.
If the call is a routine inquiry like verifying eligibility or getting claims status, an AI Voice Agent can easily engage callers in a conversational experience, provide the answers and complete the call. In order to fully automate or answer these calls, the AI Voice Agents needs to integrate with the Payer's backend systems. These include member and eligibility databases, the CCaaS System and the CRM System.
Also AI Voice Agents is no longer a technology that will only become practical in the future. Unlike other technologies, AI is gaining rapid acceptance and such natural conversational interactions are a reality today. This Generative AI based Voice Agent has already been implemented in some of the fast-moving TPAs and health plans.
Any Health Plan or TPA will want an AI Voice Agent that seamlessly integrates with the phone system or CCaaS platform being used. Modern CCaaS platforms include Five9, Genesys Cloud, Dialpad, Nice CXOne, RingCentral and Avaya.
The AI Voice Agent should be able to transfer a call over the PSTN to the appropriate queue in the CCaaS platform based on the reason for the call. And most importantly, when an Agent actually becomes available and is able to take a call that is transferred by the AI Voice Agent, the Agent should receive a "Screen Pop" of all the information or context of the interaction with the AI Voice Agent. The most frustrating thing from a user-experience standpoint is to design a system or process where the caller has to repeat information that was already provided to the AI Voice Agent.
Even after the call is answered by the human agent, the AI Voice Agent should continue to monitor and listen to the conversation between the caller and the Live Agent. In other words, it is not sufficient to just provide the context of the caller's interaction with the AI Voice Agent. It is also very important to guide and help the AI Agent in real-time. In order to do this, the AI needs to have access to the real-time audio stream, stream the audio to a Large Language model secured with adequate guardrails. As context, the LLM needs to be provided with internal knowledge-base or support articles as context.
After the call is answered by the human agent, the AI Voice Agent should automatically extract sentiment and key audio and NLU metrics and also score or rate the interaction between the caller and the Live Agent for Quality Assurance purposes.
If you are at a Health Plan or a TPA? You can experience how Casey, Voicegain's AI Voice Agent for Payers, interacts with callers in call centers today.
Here is a link to experience our demo. All it needs is 5 minutes. In-depth instructions to interact with the Demo are provided on the website.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices