On this page
IntroductionWhy a call center benchmarkMethodologyThe resultsCustom trainingOn-premises advantageStreaming performanceReproducing the benchmarkIt has been over 7 months since we published our last speech recognition accuracy benchmark. Back then the results were as follows (from most accurate to least): Microsoft and Amazon (close 2nd), then Voicegain and Google Enhanced, and then, far behind, IBM Watson and Google Standard.
Since then we have obtained more training data and added additional features to our training process. This resulted in a further increase in the accuracy of our model.
As far as the other recognizers are concerned:
- Microsoft and Amazon both improved, with Microsoft improving a lot on the more difficult files from the benchmark set
- Google has released a new model "latest-long" which is quite a bit better than the previous Google's best Video Enhanced model. Accuracy of Video Enhanced stayed pretty much unchanged.
We have decided to no longer report on Google Standard and IBM Watson accuracy, which were always far behind in accuracy.
Methodology
We have repeated the test using similar methodology as before: used 44 files from the Jason Kincaid data set and 20 files published by rev.ai and removed all files where none of the recognizers could achieve a Word Error Rate (WER) lower than 25%.
This time only one file was that difficult. It was a bad quality phone interview (Byron Smith Interview 111416 - YouTube).
The Results
You can see boxplots with the results above. The chart also reports the average and median Word Error Rate (WER)
All of the recognizers have improved (Google Video Enhanced model stayed much the same but Google now has a new recognizer that is better).
Google latest-long, Voicegain, and Amazon are now very close together, while Microsoft is better by about 1 %.
Best Recognizer
Let's look at the number of files on which each recognizer was the best one.
- Microsoft was best on 35 out of the 63 files
- Amazon was best on 15 files (note that in the October 2021 benchmark Amazon was best on 29 files).
- Voicegain was close behind Amazon by being best on 12 audio files
- Google latest-long was best on 4
- Google Video Enhanced wins a participation trophy by being best on 1 file, which was a very easy "The Art of War by Sun Tzu Full" Librivox Audiobook - WER of 1.79%
Note, the numbers do not add to 63 because there were a few files where two recognizers had identical results (to 2 digits behind comma).
Improvements over time
We now have done the same benchmark 4 times so we can draw charts showing how each of the recognizers has improved over the last 1 year and 9 months. (Note for Google the latest result is from latest-long model, other Google results are from video enhanced.)
You can clearly see that Voicegain and Amazon started quite bit behind Google and Microsoft but have since caught up.
Google seems to have the longest development cycles with very little improvement since Sept. 2021 till very recently. Microsoft, on the other hand, releases an improved recognizer every 6 months. Our improved releases are even more frequent than that.

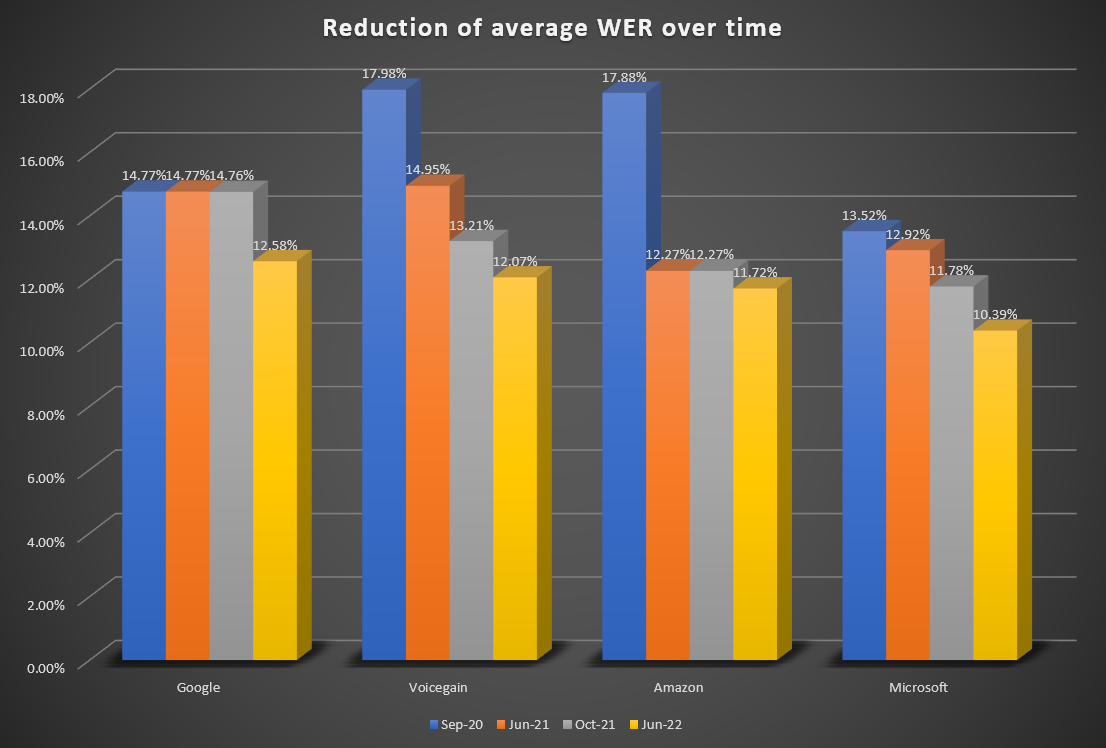
As you can see the field is very close and you get different results on different files (the average and median do not paint the whole picture). As always, we invite you to review our apps, sign-up and test our accuracy with your data.
Out-of-the-box accuracy is not everything
When you have to select speech recognition/ASR software, there are other factors beyond out-of-the-box recognition accuracy. These factors are, for example:
- Ability to customize the Acoustic Model - Voicegain model may be trained on your audio data - we have several blogposts describing both research and real use-case model customization. The improvements can vary from several percent on more generic cases, to over 50% to some specific cases, in particular for voicebots.
- Ease of integration - Many Speech-to-Text providers offer limited APIs especially for developers building applications that require interfacing with telephony or on-premise contact center platforms.
- Price - Voicegain is 60%-75% less expensive compared to other Speech-to-Text/ASR software providers while offering almost comparable accuracy. This makes it affordable to transcribe and analyze speech in large volumes.
- Support for On-Premise/Edge Deployment - The cloud Speech-to-Text service providers offer limited support to deploy their speech-to-text software in client data-centers or on the private clouds of other providers. On the other hand, Voicegain can be installed on any Kubernetes cluster - whether managed by a large cloud provider or by the client.
Take Voicegain for a test drive!
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click here to sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.
Published by