On this page
IntroductionWhy a call center benchmarkMethodologyThe resultsCustom trainingOn-premises advantageStreaming performanceReproducing the benchmarkIt is a common knowledge for AI/ML developers working with speech recognizers and ASR software that getting high accuracy in real-world applications on sequences of alphanumerics is a very difficult task. Examples of alphanumeric sequences are serial numbers of various products, policy numbers, case numbers or postcodes (e.g. UK and Canadian).
Some reasons why ASRs have a hard time recognizing alphanumerics are:
- some letters sound very similar, e.g. P and B, T and D
- A and 8 sound very similar
- combinations of letters and digits sound like words, e.g. "E Z" sounds like "easy", "B 9" sounds like "benign", etc.
Another reason why the overall accuracy is bad is simply that the errors compound - the longer the sequences the more likely it is that at least one symbol will be misrecognized and thus the whole sequence will be wrong. If accuracy of a single symbol is 90% then the accuracy of a number consisting of 6 symbols will be only 53% (assuming that the errors are independent). Because of that, major recognizers, deliver poor results on alphanumerics. In our interaction with customers and prospects, we have consistently heard about the challenges they have encountered with getting good accuracy on alphanumeric sequences. Some of them use post-processing of the large vocabulary results, in particular, if a set of hypotheses is returned. We used such approaches back when we built IVR systems as Resolvity and had to use 3rd party ASR. In fact, we were awarded with a patent for one of such postprocessing approaches.
Case Study: British Postcodes
While working on a project aiming to improve recognition of UK postcodes we collected over 9000 sample recordings of various people speaking randomly selected valid UK postcodes. About 1/3 of speakers had British accent, while the remaining had a variety of other accents, e.g. Indian, Chinese, Nigerian, etc.
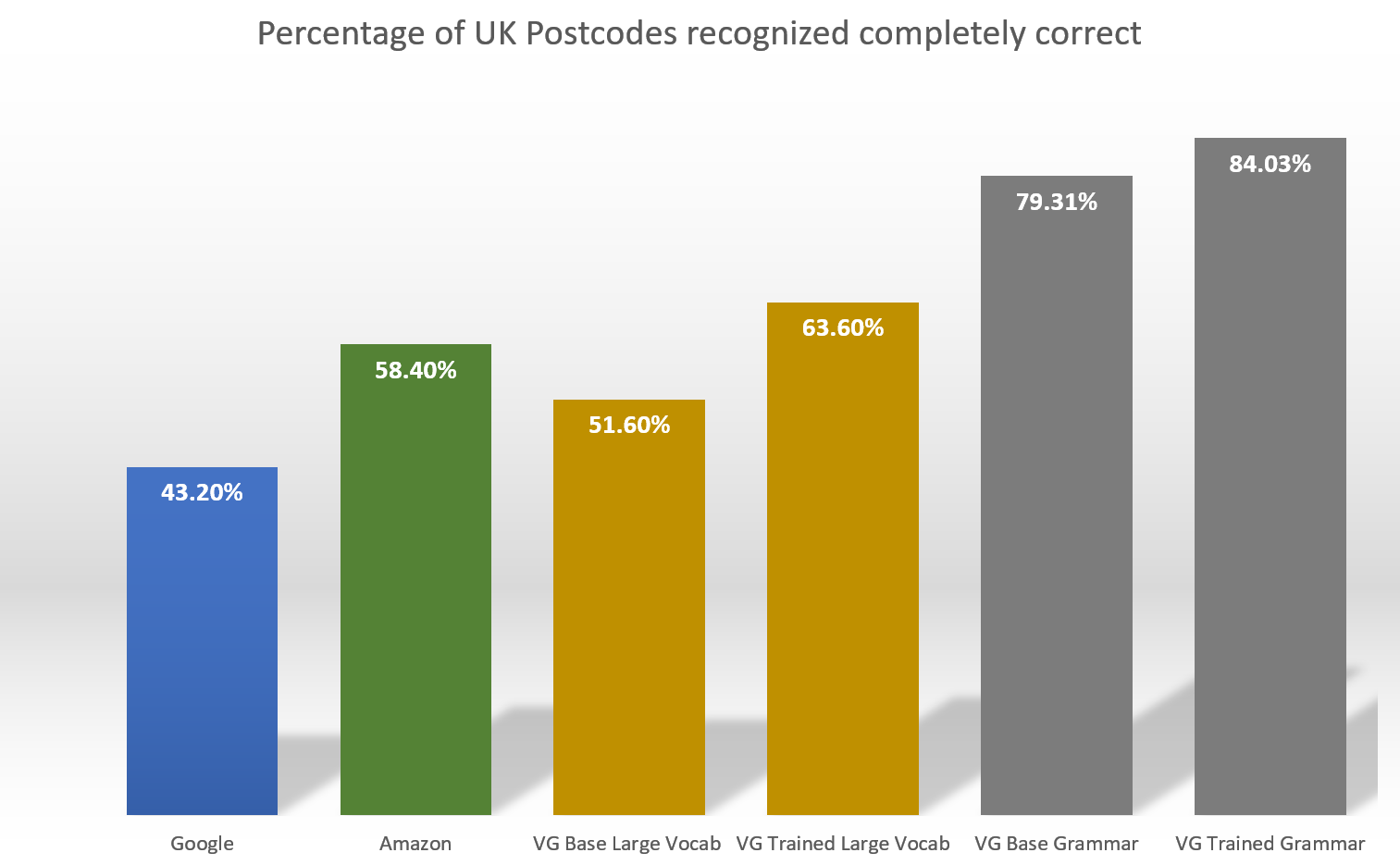
Out of that data set we reserved some for testing. The results reported here are from a 250 postcode test set (we will soon provide a link to this test set on our Github). As of the date of this blog post, Google Speech-to-Text achieved only 43% accuracy and Amazon 58% on this test set.
At Voicegain we use two approaches to help us achieve high accuracy on the alphahumerics: (a) training the recognizer on realistic data sets containing sample alphanumeric sequences, (b) using grammars to constrain the possible recognitions. In a specific scenario, we can use one or the other or even both approaches.
Here is a summary of the results that we achieved on the UK postcodes set.
Improving Recognition with Acoustic Model Training
We used the data set described above in our most recent training round for our English Model and have achieved significant improvement in accuracy when testing on a set of 250 UK postcodes which were not used in training.
- For unconstrained large vocabulary recognition the accuracy improved from 51.60% to 63.60% (a gain of 12%). The training helped both the acoustic part of our model (e.g. letters which were skipped in the base recognizer because they were not enunciated well enough were picked after training - 8 was recognized correctly instead of H, etc.) and the language part of our model (e.g. correctly recognizing "two" instead of "to" because of the context)
- For grammar-based recognition (more about it in the section below) the accuracy improved from 79.31% to 84.03% (a gain of 4.72%). Because in grammar based recognition the language model is fully defined by the grammar the gain here was from being able to distinguish more acoustic nuances between various letters and numbers (e.g. someone's long R is no longer recognized as "A R", "L P" is now correctly recognized instead of "A P", etc).
Improving Recognition with the use of Grammars
Voicegain DNN recognizer has ability to use grammars for speech recognition, a somewhat unique feature among modern speech recognizers. We support GRXML and JSGF grammar format. Grammars are used during the search - they are not merely applied to the result of the large vocabulary recognition - this gives us best possible results. (BTW, we can also combine grammar-based recognition with large vocabulary recognition, see this blog post for more details.)
For UK postcode recognition we defined a grammar which captures all ways in which valid UK postcodes can be said. You can see the exact grammar that we used here.
Grammar based UK postcode recognition gives significantly better results than large vocabulary recognition.
- On our base model, before training, the difference was 27.71% (79.31% vs 51.60%)
- On the trained model the difference was smaller, but still very large 20.43% (84.03% vs 63.60%)
- Compared to Amazon recognizer we were 25.62% better after training (84.03% vs 58.40%)
What if the possible set of alphanumeric sequences cannot be defined using a grammar?
We have come across scenarios where the alphanumeric sequences are difficult to define exhaustively using grammars, e.g. some Serial Numbers. In those cases our recognizer supports the following approach:
- Define a grammar that matches a superset of valid sequences,
- Use a lookup table to match know list of valid and likely to occur sequences. For example, if these are serial numbers and the application deals with warranty registration, we can narrow down a set of possible SN that we may have to recognize.
Want to test your alphanumeric use case?
We are always ready to help prospective customers with solving their challenges with speech recognition. If your current recognizer does not deliver satisfactory results recognizing sequences of alphanumerics, start a conversation over email at info@voicegain.ai. We are always interested in accuracy.
Published by