
Han pasado más de 7 meses desde que publicamos nuestra última precisión de reconocimiento de voz punto de referencia. En aquel entonces, los resultados eran los siguientes (del más preciso al menos preciso): Microsoft y Amazon (casi en segundo lugar), luego Voicegain y Google Enhanced, y luego, muy por detrás, IBM Watson y Google Standard.
Desde entonces, hemos obtenido más datos de formación y hemos añadido funciones adicionales a nuestro proceso de formación. Esto se tradujo en un aumento adicional en la precisión de nuestro modelo.
En lo que respecta a los demás reconocedores:
Hemos decidido dejar de informar sobre la precisión de Google Standard e IBM Watson, que siempre estuvieron muy por detrás en cuanto a precisión.
Hemos repetido la prueba con una metodología similar a la anterior: utilizamos 44 archivos del Conjunto de datos de Jason Kincaid y 20 archivos publicado por rev.ai y eliminó todos los archivos en los que ninguno de los reconocedores podía alcanzar una tasa de errores de palabras (WER) inferior al 25%.
Esta vez solo un archivo fue tan difícil. Fue una entrevista telefónica de mala calidad (Entrevista a Byron Smith (111416 - YouTube).
Puedes ver diagramas de caja con los resultados de arriba. El gráfico también muestra el promedio y la mediana de la tasa de errores de palabras (WER)
Todos los reconocedores han mejorado (el modelo de Google Video Enhanced se mantuvo prácticamente igual, pero Google ahora tiene un nuevo reconocedor que es mejor).
Google, de última generación, Voicegain y Amazon están ahora muy cerca, mientras que Microsoft es mejor en aproximadamente un 1%.
Veamos la cantidad de archivos en los que cada reconocedor era el mejor.
Tenga en cuenta que los números no suman 63 porque había algunos archivos en los que dos reconocedores arrojaban resultados idénticos (con 2 dígitos detrás de una coma).
Ahora hemos realizado el mismo punto de referencia 4 veces para poder dibujar gráficos que muestren cómo cada uno de los reconocedores ha mejorado en los últimos 1 año y 9 meses. (Ten en cuenta que para Google el último resultado proviene del modelo más reciente y otros resultados de Google provienen de vídeos mejorados).
Puedes ver claramente que Voicegain y Amazon empezaron bastante por detrás de Google y Microsoft, pero desde entonces se han puesto al día.
Google parece tener los ciclos de desarrollo más largos, con muy pocas mejoras desde septiembre de 2021 hasta hace muy poco. Microsoft, por otro lado, lanza un reconocedor mejorado cada 6 meses. Nuestras versiones mejoradas son incluso más frecuentes que eso.


Como puede ver, el campo está muy cerca y se obtienen resultados diferentes en diferentes archivos (el promedio y la mediana no muestran el panorama completo). Como siempre, te invitamos a revisa nuestras aplicaciones, regístrate y compruebe nuestra precisión con sus datos.
Cuando tiene que seleccionar el software de reconocimiento de voz/ASR, hay otros factores que van más allá de la precisión del reconocimiento lista para usar. Estos factores son, por ejemplo:
1. Haga clic aquí para obtener instrucciones sobre cómo acceder a nuestro sitio de demostración en vivo.
2. Si estás creando una aplicación de voz genial y quieres probar nuestras API, haz clic aquí para crear una cuenta de desarrollador y recibir 50$ en créditos gratis
3. Si quieres usar Voicegain como tu propio asistente de transcripción con IA para las reuniones, haz clic aquí.

Muchos de nuestros clientes nos han pedido ayuda para comparar el reconocedor de voz a texto (ASR) Voicegain en sus archivos de audio específicos. Para facilitar esta evaluación comparativa, hemos publicado un script de Python que logra precisamente eso. Con una sola línea de comandos, puede transcribir todos los archivos de audio del directorio de entrada y compararlos con las transcripciones de referencia, calculando el WER de cada archivo. También puedes hacer una comparación bidireccional entre la transcripción de referencia y la transcripción de Voicegain y la transcripción de Google Speech-to-Text.
El guion y la documentación están disponibles en: https://github.com/voicegain/platform/tree/master/utility-scripts/test-transcribe
Ver nuestra publicación de blog de referencia para darte una idea del tipo de precisión que puedes esperar del reconocedor Voicegain.
Actualizado el 28 de febrero de 2022
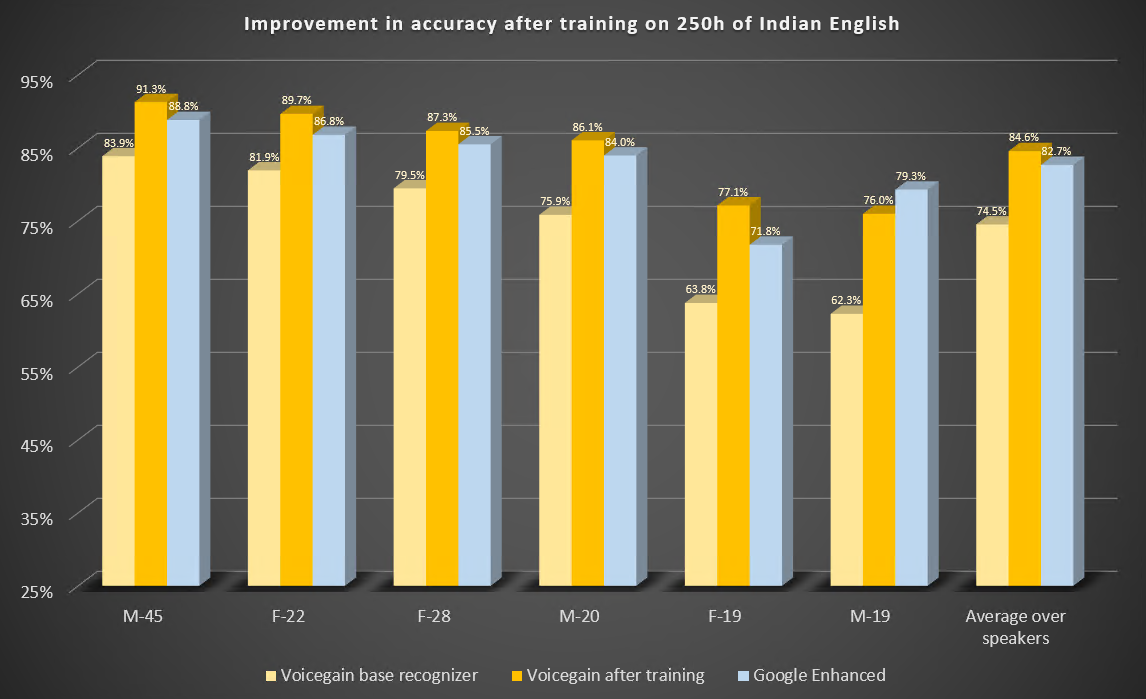
En esta entrada de blog, describimos dos estudios de casos para ilustrar las mejoras en la precisión del reconocimiento de voz a texto o ASR que se pueden esperar del entrenamiento de los modelos acústicos subyacentes. Entrenamos nuestro modelo acústico para que reconociera mejor el inglés indio e irlandés.
El modelo acústico Voicegain listo para usar, que está disponible de forma predeterminada en la plataforma Voicegain, fue entrenado para reconocer principalmente el inglés estadounidense, aunque nuestro conjunto de datos de entrenamiento contenía algo de audio en inglés británico. Los datos de entrenamiento no contenían el inglés indio ni el irlandés, excepto quizás en casos fortuitos.
Ambos estudios de caso se realizaron de manera idéntica:
Estos son los parámetros de este estudio.
Estos son los resultados del punto de referencia antes y después del entrenamiento. A modo de comparación, también incluimos los resultados de Google Enhanced Speech-to-Text.
Algunas observaciones:
Estos son los parámetros de este estudio.
Estos son los resultados del punto de referencia antes y después del entrenamiento. También incluimos los resultados de Google Enhanced Speech-to-Text.
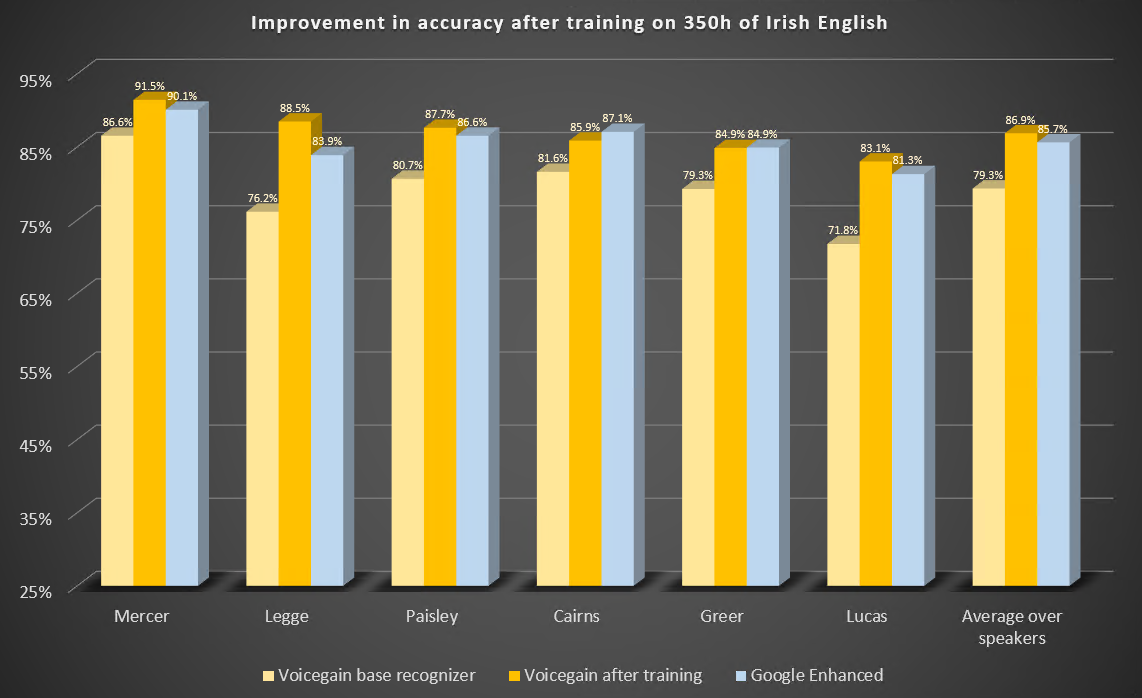
Algunas observaciones:
Hemos publicado 2 estudios adicionales que muestran los beneficios del entrenamiento con modelos acústicos:
1. Haga clic aquí para obtener instrucciones sobre cómo acceder a nuestro sitio de demostración en vivo.
2. Si estás creando una aplicación de voz genial y quieres probar nuestras API, haz clic aquípara crear una cuenta de desarrollador y recibir 50$ en créditos gratis
3. Si quieres usar Voicegain como tu propio asistente de transcripción con IA para las reuniones, haz clic aquí.

En nuestro post anterior describimos cómo Voicegain proporciona un reconocimiento de voz basado en la gramática a la plataforma de voz programable Twilio a través del Transmisión multimedia de Twilio Característica.
A partir de versión 1.16.0 <Gather>de la plataforma y API Voicegain, es posible usar Voicegain de voz a texto para la transcripción de voz (sin gramáticas) para lograr funciones como el uso de TWiML.
Las razones por las que creemos que será atractivo para los usuarios de Twilio son:
El uso de Voicegain como alternativa a <Gather>tendrá pasos similares a los de usar Voicegain para el reconocimiento basado en la gramática; estos pasos se enumeran a continuación.
Esto se hace invocando la API de transcripción asíncrona de Voicegain: /asr/transcribir/asincrónico
A continuación se muestra un ejemplo de la carga útil necesaria para iniciar una nueva sesión de transcripción:
Algunas notas sobre el contenido de la solicitud:
Esta solicitud, si se realiza correctamente, devolverá la URL del websocket en el campo audio.stream.websocketURL. Este valor se utilizará para realizar una solicitud de TWiML.
Tenga en cuenta que, en el modo de transcripción, la detección de DTMF no es posible actualmente. Háganos saber si esto es algo que sería fundamental para su caso de uso.
Tras iniciar una sesión de Voicegain ASR, podemos decirle a Twilio que abra la conexión de Media Streams con Voicegain. Esto se hace mediante la siguiente solicitud de TWiML:
Algunas notas sobre el contenido de la solicitud de TWiML:
A continuación se muestra un ejemplo de respuesta de la transcripción en el caso de que «content»: {"full»: ["transcript"]}.

Queremos compartir un breve vídeo que muestra la transcripción en directo en acción en CBC. Este utiliza nuestro modelo acústico de referencia. No se realizó ninguna personalización ni se utilizaron sugerencias. Este vídeo da una idea de la latencia que se puede lograr con la transcripción en tiempo real.
La transcripción automatizada en tiempo real es una excelente solución para personas con problemas de audición si no hay un intérprete de lenguaje de señas disponible. Se puede usar, por ejemplo, en iglesias para transcribir sermones, en convenciones y reuniones para transcribir charlas, en instituciones educativas (escuelas, universidades) para transcribir lecciones y conferencias en vivo, etc.
La plataforma Voicegain ofrece un paquete completo para admitir la transcripción en vivo:
Se puede lograr una precisión muy alta, superior a la proporcionada por Google, Amazon y Microsoft Cloud de voz a texto, mediante Personalización del modelo acústico.

Voicegain añade el reconocimiento de voz basado en la gramática a la plataforma de voz programable Twilio a través del Transmisión multimedia de Twilio Característica.
La diferencia entre el reconocimiento de voz Voicegain y Twilio Twiml <Gather> es:
Cuando utilices Voicegain con Twilio, la lógica de tu aplicación tendrá que gestionar las solicitudes de devolución de llamadas tanto de Twilio como de Voicegain.
Cada reconocimiento implicará dos pasos principales que se describen a continuación:
Esto se hace invocando la API de reconocimiento asíncrono de Voicegain: /asr/recognize/async
A continuación se muestra un ejemplo de la carga útil necesaria para iniciar una nueva sesión de reconocimiento:
Algunas notas sobre el contenido de la solicitud:
Esta solicitud, si se realiza correctamente, devolverá la URL del websocket en el campo audio.stream.websocketURL. Este valor se utilizará para realizar una solicitud de TWiML.
Tenga en cuenta que si la gramática se especifica para reconocer el DTMF, el reconocedor Voicegain reconocerá las señales DTMF incluidas en el audio enviado desde la plataforma Twilio.
Tras iniciar una sesión de Voicegain ASR, podemos decirle a Twilio que abra la conexión de Media Streams con Voicegain. Esto se hace mediante la siguiente solicitud de TWiML:
Algunas notas sobre el contenido de la solicitud de TWiML:
A continuación se muestra un ejemplo de respuesta del reconocimiento. Esta respuesta proviene de la gramática telefónica integrada.

Algunos de los comentarios que recibimos sobre los datos de referencia publicados anteriormente, consulte aquí y aquí, se refería al hecho de que el Conjunto de datos de Jason Kincaid contenía algo de audio que producía un WER terrible en todos los reconocedores y, en la práctica, nadie utilizaría el reconocimiento de voz automático en esos archivos. Eso es cierto. En nuestra opinión, hay muy pocos casos de uso en los que un WER inferior al 20%, es decir, en los que una media de 1 de cada 5 palabras se reconoce incorrectamente, sea aceptable.
Lo que hemos hecho para esta entrada de blog es eliminar del conjunto denunciado aquellos archivos de referencia para los que ninguno de los reconocedores probados podía ofrecer un WER del 20% o menos. Como resultado de este criterio, se eliminaron 10 archivos: 9 del conjunto de 44 de Jason Kincaid y 1 archivo del conjunto de 20 de rev.ai. Los archivos eliminados se dividen en 3 categorías:
Como puede ver, los reconocedores de Voicegain y Amazon coinciden de manera muy uniforme, con un WER promedio que difiere solo en un 0,02%, lo mismo ocurre con los reconocedores de Google Enhanced y Microsoft, con una diferencia de WER de solo el 0,04%. El WER de Google Standard es aproximadamente el doble que el de los demás reconocedores.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →¿Está interesado en personalizar el ASR o implementar Voicegain en su infraestructura?

Voicegain ayuda a los desarrolladores a crear increíbles aplicaciones compatibles con la voz al proporcionarles la plataforma de conversión de voz a texto más precisa, asequible y accesible.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices