Actualizado el 28 de febrero de 2022
En esta entrada de blog, describimos dos estudios de casos para ilustrar las mejoras en la precisión del reconocimiento de voz a texto o ASR que se pueden esperar del entrenamiento de los modelos acústicos subyacentes. Entrenamos nuestro modelo acústico para que reconociera mejor el inglés indio e irlandés.
Configuración del estudio de caso
El modelo acústico Voicegain listo para usar, que está disponible de forma predeterminada en la plataforma Voicegain, fue entrenado para reconocer principalmente el inglés estadounidense, aunque nuestro conjunto de datos de entrenamiento contenía algo de audio en inglés británico. Los datos de entrenamiento no contenían el inglés indio ni el irlandés, excepto quizás en casos fortuitos.
Ambos estudios de caso se realizaron de manera idéntica:
- Los datos de entrenamiento contenían aproximadamente 300 horas de audio de voz transcrito.
- La capacitación se realizó para mejorar la precisión en el nuevo tipo de datos, pero al mismo tiempo para mantener la precisión de referencia. Una alternativa habría consistido en tratar de mejorar al máximo los nuevos datos a expensas de la precisión del modelo de referencia.
- La capacitación se interrumpió después de lograr una mejora significativa. Se podría haber seguido logrando una mejora adicional, aunque podría haber sido marginal.
- Los puntos de referencia que se presentan aquí se realizaron con datos que no se incluyeron en el conjunto de capacitación.
Estudio de caso 1: inglés indio
Estos son los parámetros de este estudio.
- Teníamos 250 horas de audio con oradores masculinos y femeninos, y cada orador leía unos 50 minutos de audio de voz.
- Separamos 6 altavoces para el punto de referencia, seleccionando 3 muestras masculinas y 3 femeninas. Las muestras se seleccionaron para incluir casos de prueba fáciles, medios y difíciles.
Estos son los resultados del punto de referencia antes y después del entrenamiento. A modo de comparación, también incluimos los resultados de Google Enhanced Speech-to-Text.
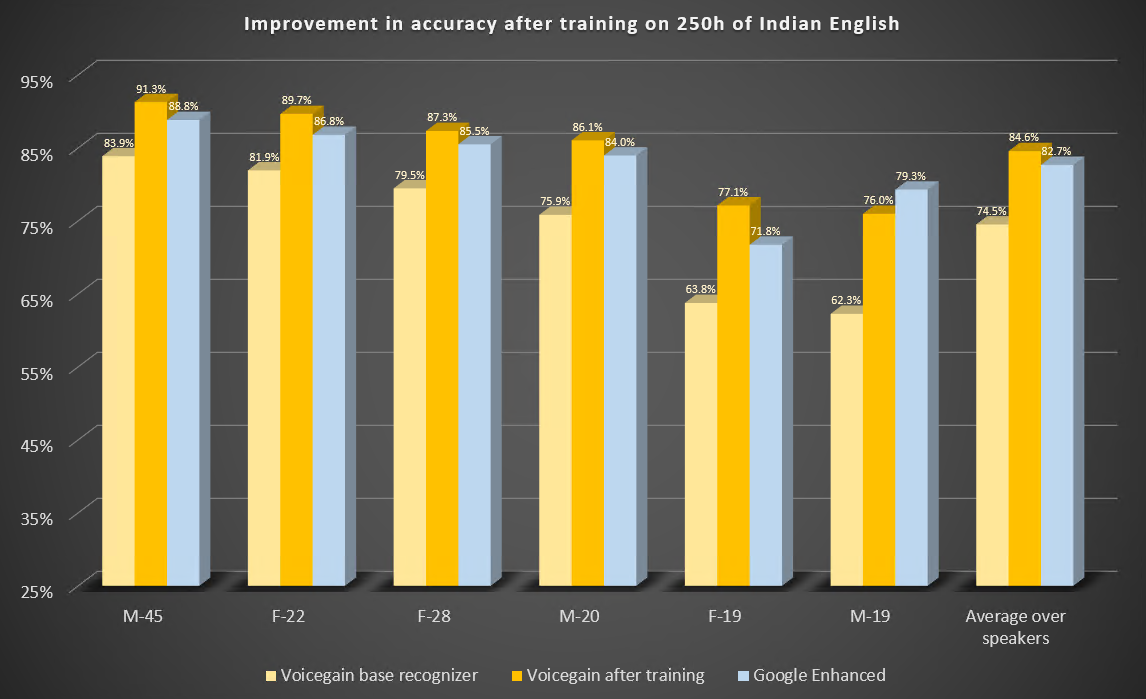
Algunas observaciones:
- Los 6 altavoces de prueba muestran una mejora significativa con respecto a la precisión original.
- Después del entrenamiento, la precisión de 5 altavoces es mejor que la de Google Enhanced Speech-to-Text. El único orador que quedaba mejoró considerablemente (del 62% al 76%), pero la precisión siguió sin ser tan buena como la de Google. Examinamos el audio y resulta que no se grabó correctamente. El altavoz hablaba en voz muy baja y la ganancia del micrófono era muy alta, por lo que el audio contenía muchos artefactos extraños, como, por ejemplo, un chasquido con la lengua. El orador también preparaba el texto de una manera «mecánica» muy poco natural. Felicitaciones a Google por hacerlo tan bien en una grabación tan mala.
- De media, la conversión de voz a texto Voicegain con formación personalizada obtuvo una mejora de aproximadamente un 2% en nuestra referencia de inglés indio en comparación con el reconocedor mejorado de Google.
Estudio de caso 2: inglés irlandés
Estos son los parámetros de este estudio.
- Recopilamos alrededor de 350 horas de audio de voz transcrito de un orador de Irlanda del Norte.
- Para el punto de referencia, conservamos parte del audio de ese altavoz que no se usó para el entrenamiento y, además, encontramos el audio de otros 5 altavoces con varios tipos de acentos en inglés irlandés.
Estos son los resultados del punto de referencia antes y después del entrenamiento. También incluimos los resultados de Google Enhanced Speech-to-Text.
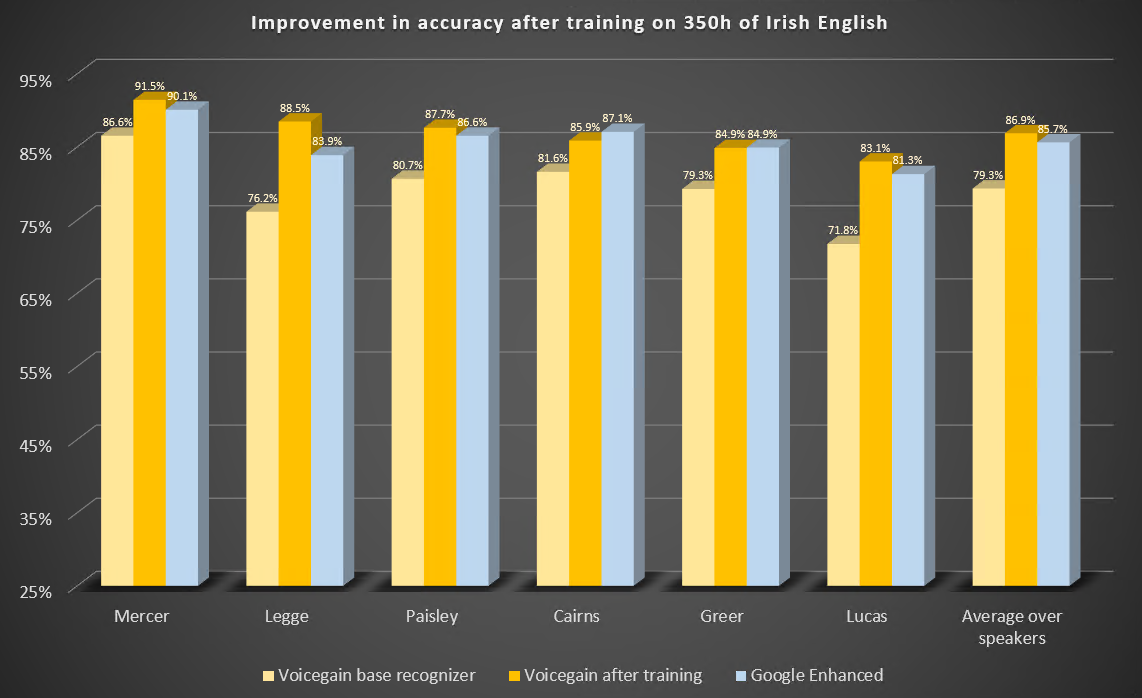
Algunas observaciones:
- El altavoz que se usó para el entrenamiento está etiquetado aquí como «Legge». Tras el entrenamiento, observamos una enorme mejora, pasando del 76,2% al 88,5%, una cifra muy superior a la de Google Enhanced, con un 83,9%
- El otro orador con una mejora de más del 10% es «Lucas», que tiene un acento muy similar al de «Legge».
- Analizamos en detalle el audio del altavoz con la etiqueta «Cairns» que menos había mejorado y para el que Google era mejor que nuestro reconocedor personalizado. El audio tiene una calidad significativamente inferior a la de las demás muestras, además de que contiene un eco notable. Sus características de audio son bastante diferentes de las características de audio de los datos de entrenamiento utilizados.
- De media, la conversión de voz a texto de Voicegain con formación personalizada obtuvo una mejora de aproximadamente un 1% en nuestro punto de referencia en inglés irlandés en comparación con el reconocedor mejorado de Google.
Observaciones adicionales
- La cantidad de datos utilizada en el entrenamiento de 250 a 350 horas no fue grande, dado que normalmente los modelos acústicos para el reconocimiento de voz se entrenan con decenas de miles de horas de audio.
- La gran mejora con respecto al altavoz «Legge» sugiere que si el objetivo es mejorar el reconocimiento de un tipo de voz o altavoz muy específico, el tiempo de entrenamiento podría ser menor, tal vez de 50 a 100 horas, para lograr una mejora significativa.
- Es posible que se necesite un conjunto de entrenamiento más grande (500 horas o más) en los casos en que la variabilidad del habla y otras características de audio sea grande.
ACTUALIZACIÓN: febrero de 2022
Hemos publicado 2 estudios adicionales que muestran los beneficios del entrenamiento con modelos acústicos:
- Conseguir una alta precisión de reconocimiento de voz en secuencias alfanuméricas: un estudio de caso con códigos postales del Reino Unido
- El entrenamiento con modelos ofrece enormes ganancias en precisión: estudio de caso: Indian Food Bot
¿Te interesa Voicegain? ¡Llévanos a hacer una prueba de manejo!
1. Haga clic aquí para obtener instrucciones sobre cómo acceder a nuestro sitio de demostración en vivo.
2. Si estás creando una aplicación de voz genial y quieres probar nuestras API, haz clic aquípara crear una cuenta de desarrollador y recibir 50$ en créditos gratis
3. Si quieres usar Voicegain como tu propio asistente de transcripción con IA para las reuniones, haz clic aquí.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices