
This article outlines how the modern Voicegain deep-learning based Speech-to-Text/ASR can be a simple and affordable alternative for businesses that are looking for a quick and easy replacement to their on-premise Nuance Recognizer. Nuance has announced that its going to end support for Nuance Recognizer, its grammar-based ASR which uses the MRCP protocol, sometime in 2026 or 2027. So organizations that have a Speech-enabled IVR as their front door to the contact center need to start planning now.
With the rise of Generative AI and highly accurate low latency speech-to-text models, the front door of the call center is poised for major transformation. The infamous and highly frustrating IVR phone menu will be replaced by Conversational AI Voicebots; but this will likely happen over the next 3-5 years. As enterprises start to plan their migration journey from these tree-based IVRs to an Agentic AI future, they would like to do this on their timelines. In other words, they do not want to be forced to do this under the pressure of a deadline because of EOL of their vendor.
In addition, the migration path proposed by Nuance is a multi-tenant cloud offering. While a cloud based ASR/Speech-to-Text engine is likely to make sense for most businesses, there are companies in regulated sectors that are prevented from sending their sensitive audio data to a multi-tenant cloud offering.
In addition to the EOL announcement by Nuance for their on-premise ASR, a major IVR platform vendor like Genesys has also announced that its premise-based offerings - Genesys Engage and Genesys Connect - will also approach EOL at the same time as the Nuance ASR.
So businesses that want a modern Gen AI powered Voice Assistant but want to keep the IVR on-premise in their datacenter or behind their firewall in a VPC will need to start planning very quickly what their strategy is going to be.
At Voicegain, we allow enterprises that are in this situation and want to remain on-premise or in their VPC with a modern Voicebot platform. This Voicebot platform runs on modern Kubernetes clusters and leverages the latest NVIDIA GPUs.
Rewriting the IVR Application logic to migrate from a tree-based IVR menu to a conversational Voice Assistant is a journey. It would require investments and allocation of resources. Hence a good first step is to simply replace the underlying Nuance ASR (and possibly the IVR platform too). This will guarantee that a company can migrate to a modern Gen-AI Voice Assistant on its timelines.
Voicegain offers a modern highly accurate deep-learning-based Speech-to-text engine trained on hundreds of thousands of hours of telephone conversations. It is integrated into our native modern telephony stack. It can also talk over the MRCP protocol with VoiceXML based IVR platforms and it supports the traditional Speech grammars (SRGS, JJSGF). Voicegain also supports a range of built-in grammars (like Zipcode, Dates etc).
As a result, it is a simple "drop-in" replacement to the Nuance Recognizer. There is no need to rewrite the current IVR application. Instead of pointing to the IP address of the Nuance Server, the VoiceXML platform just needs to be reconfigured to point to the IP address of the Voicegain ASR server. This should take no more than a couple of minutes.
In addition to the Voicegain ASR/STT engine, we also offer a Telephony Bot API. This is a callback style API that includes our native IVR platform and ASR/STT engine can be used to build Gen AI powered Voicebots. It integrates with leading LLMs - both cloud and open-source premise based - to drive a natural language conversation with the callers.
If you would like to discuss your IVR migration journey, please email us at sales@voicegain.ai . At Voicegain, we have decades of experience in designing, building and launching conversational IVRs and Voice Assistants.
Here is also a link to more information. Please feel free to schedule a call directly with one of our Co-founders.

Developers building voice-enabled SaaS applications that embed Speech-to-Text or Transcription as part of their product have multiple vendors to choose from.
However, the decision to pick the right Speech-to-Text platform or API is rather involved. This writeup outlines three types of vendors and the three key criteria (summarized as the 3 As - Accuracy, Affordability and Accessibility) to consider while making that choice.
Most voice-enabled SaaS apps that incorporate Speech-to-Text APIs broadly fall into two categories 1) Analytics and 2) Automation.
Whether you are developing an analytics app or an automation app, developers have the following vendor choices.
There are 3 distinct types of vendors

The first set of choices for most developers are Speech-to-Text APIs from the big cloud companies - Google, Amazon and Microsoft. These big players offer Speech-to-Text APIs as part of their portfolio of Cloud AI & ML services. The strategy for the Big Cloud providers is to sell their entire stack - from cloud infrastructure to APIs and even products.
However the Cloud service providers may compete directly with the developers they look to serve. E.g. Amazon Connect directly competes with Contact Center platforms that are hosted on AWS. Google Dialogflow directly competes with other NLU startups that may be looking to build and offer Voice bots and Voice Assistants to enterprises.
Other than the big 3, Nuance and IBM Watson are large companies that have a rich history of providing Automated Speech Recognition (ASR). Of the two, Nuance is better known and has been a dominant player both in the enterprise call center market with its Nuance ASR engine and in the medical transcription space with its Dragon offering. IBM has a long history of fundamental speech recognition and IBM Watson Speech-to-Text is their developer oriented offering.
Voicegain.ai, our company, plays alongside other startup companies like Deepgram that target SaaS developers with their best-of-breed DNN based speech-to-text. Since these startups are specialized providers, they are focused on beating the big cloud providers and legacy players with respect to price, performance and ease of use.
The key criteria while picking an ASR or Speech-to-Text platform are the 3 As - Accuracy, Affordability and Accessibility.
The first and most important criteria for any Speech-to-Text platform is recognition accuracy. However accuracy is a tricky metric to assess and measure. There is no 'one-size-fits-all' approach to accuracy. We have shared our thoughts & benchmarks here. While Voicegain matches or exceeds the "out-of-the-box" transcription accuracy of most of the larger players, we suggest that you do additional diligence before making a choice. The audio datasets used in these benchmarks may or may not be similar to the use case or context for which the developer intends to use the API.
While accuracy is usually measured using Word Error Rate (WER), it is important to note that this metric too has limitations. For a SaaS app, getting some important and critical words right may be even more important than just a low overall WER.
That being said, it is important for developers to establish and calculate a quick baseline "out-of-the-box" accuracy for their application with their audio datasets.
At Voicegain, we have open sourced tools to benchmark our performance against the very best in business. We strongly recommend that developers & ML Engineers calculate a benchmark baseline accuracy for their vendor choices using a statistically significant volume of audio datasets for their application.
From a developer perspective, a baseline accuracy measure will provide insights into the how closely your datasets match the datasets that the underlying STT models from the vendors have been trained on.
Here are a set of important factors that may affect your "out-of-the-box" accuracy:
Developers also need to establish a "Target" accuracy that their SaaS application or product requires. Usually Product Managers determine this based on their needs.
It is possible to bridge the gap between the Target Accuracy and the Baseline "out-of-the-box" accuracy. While it is outside the scope of this post, here is an overview of some ways in which developers can improve upon the Baseline accuracy.
However not all Speech-to-Text platforms support one or more of these options.
At Voicegain.ai, we support all the above options. Picking the right approach involves a more in-depth technical conversation. We invite you to get in touch with us.
To summarize, the choice may not be as simple as picking the one with the best "out-of-the-box' accuracy. It could in fact be a platform that provides the most convenient and least expensive path to bridge the gap between Target and Baseline accuracy.
The second most important factor after accuracy is price. Most SaaS products are very disruptively priced. It is not uncommon for the SaaS product to be sold at 'tens of dollars' ($35-100) per user per month. It is critical that Speech-to-Text APIs make up as small a fraction of the SaaS price as possible. The price directly impacts the "gross-margin" of the SaaS application, a critical financial metric/KPI that SaaS companies care dearly about.
In addition to the top-line usage based price for the platform, it is also important to understand what the minimum billable time and billing increment for each interaction. Many of the large Cloud providers have a very high minimum billable times - 12 or 18 seconds. This makes it very expensive for Voice Bots or Voice Assistant.
Another cost related aspect is the price for transcribing multi-channel audio, where only one speaker is active at the time. Does the platform charge for transcribing silence on the inactive channel ?
The last (but not the least!) important criterion is how accessible - or in other words how simple and easy is it to integrate the Speech-to-Text platform with the SaaS Application.
This ease of integration becomes even more important if the SaaS Application streams audio real-time to the Speech-to-Text platform. Another important criterion for real-time streaming is latency - which is the time to receive recognition results from the platform. For a Bot or Voice Assistant, it is important to get API latency down to 500 milliseconds or lower. Also, reliable and fast end-of-speech detection is crucial in those scenarios for natural dialog turn taking.

At Voicegain, we support multiple options - ranging from TCP-based methods like gRPC and Websockets to telephony/UDP protocols like SIP/RTP, MRCP and SIPREC.
The choice made by the developer depends on the following factors:
In conclusion, selecting the right Speech-to-Text or ASR platform for a SaaS application is a diligent exercise; it is by no means a slam dunk!!
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

Voicegain Speech-to-Text and Speech Analytics platform supports SIPREC protocol as one of the ways an audio stream of a telephone call can be fed to the speech recognizer.
The Session Recording Protocol (SIPREC) is an open SIP-based protocol for call recording. The standard is defined by Internet Engineering Task Force. It is supported by many phone platforms and call recording system vendors.
The SIPREC standard defines a protocol used to interact between a Session Recording Client (the role generally performed by PBX system or Session Border Controller) and a Session Recording Server (a third party call recorder, in our case a Voicegain-provided SIPREC server). SIPREC opens two RTP streams (one for inbound and one for outbound audio of the call) to the Recording Server. SIPREC protocol also is able to transfer call metadata to the Recorder, this is important so that the recordings can be tied to the information about the calls.
SIPREC is usually used for call recording but the standard essentially provides a real-time audio stream from the telephone call which makes it suitable for applications which have to work real-time like, e.g., agent assist or agent monitoring. Using the SIPREC interface Voicegain can provide real-time transcript of the call as well as perform speech analytics tasks in real time, e.g., keyword and phrase detection, personally-identifiable information scrubbing, sentiment and mood estimation, named-entity recognition, and variety of metrics (like silence, overtalk, etc.).
Audio obtained via SIPREC can also be recorded and transcribed, analyzed, or retrieved at a later time.
Voicegain SIPREC interface has been tested with the following platforms:
Voicegain can capture relevant call metadata in addition to obtaining the audio (the metadata capture functionality may differ in capabilities depending on the client platform).
Voicegain platform can be configured to automatically launch transcription and speech-analytics as soon as the new SIPREC session gets established.
The output from transcription and speech analytics is available via a Web API. We also support websockets for more convenient streaming of the transcription and/or speech analytics data. SIPREC support is available both in the Cloud and the Edge (OnPrem) deployments of the Voicegain Platform.
SIPREC is an Enterprise feature of the Voicegain platform and is not included in the base package. Please contact support@voicegain.ai or submit a Zendesk ticket for more information about SIPREC and if you would like to use it with your existing Voicegain account.
Genesys Voice Platform does not support SIPREC directly. However, it does support streaming of the inbound and outbound RTP media to two separate SIP endpoints - the end result being pretty much the same as if SIPREC was used. We are currently working on implementing support for this feature of the Genesys Voice Platform for real-time audio streaming to Voicegain Platform. It should be available in Q1 2021.

In latest Voicegain release (1.16.0) we have added a new option to our /asr/recognize/async API for ASR/speech-to-text. It is called continuousRecognition and if enabled modifies the default behavior of the grammar-based recognition.
Normally when /asr/recognize/async API is used the recognizer will return when the grammar is matched and the complete timeout expires. That means that it is only possible to get a single recognition in one /asr/recognize/async API request. If a no-match or no-input is detected the recognition will terminate.
However, sometimes there are use cases which demand that the recognizer e.g. ignores all no-matches until a match is found. This is what the continuousRecognition option is for.
With continuousRecognition you have fine control over which of the 4 events - no-input, no-match, match, and error - will be returned in a callback and which (if any) event will terminate recognition. If you do not set any event to terminate recogntion, the recognition session can be stopped by closing the audio stream or by returning stop:true from the callback.
An example might be a use case where a voicemail is being played to a caller and during the playback we want to interpret caller commands like: stop, next, previous, save, delete. If we used normal recognition we would encounter situations where what is said was not understood. Stopping recognition on no-match would not make much sense because either: (1) re-prompting would mess up the flow of the call, or (2) restarting recognition might introduce a gap in recognition that may result in missing a part what the caller said.
In scenario like this it is best to ignore no-match and continue to listen, the caller will notice no response to what he said and will naturally repeat that.
The settings for continuous recognition that would work in this case would be:
Continuous Recognition is supported in Voicegain integration for Twilio Media Streams - either TwiML <Stream> or <Connect><Stream> in Twilio Programmable Voice
It is not yet supported in Voicegain Telephony Bot APIs.

Many of our customers have been asking us for help in benchmarking Voicegain speech-to-text recognizer (ASR) on their specific audio files. To make this benchmarking easier we have released a python script that accomplishes just that. With a single command line you can transcribe all audio files from the input directory and compare them against reference transcripts - calculating the WER for each file. You can also do a 2-way comparison of reference vs Voicegain transcript vs Google Speech-to-Text transcript.
The script and the documentation is available at: https://github.com/voicegain/platform/tree/master/utility-scripts/test-transcribe
See our benchmark blog post to give you an idea of what kind of accuracy to expect from the Voicegain recognizer.
Updated: Feb 28 2022
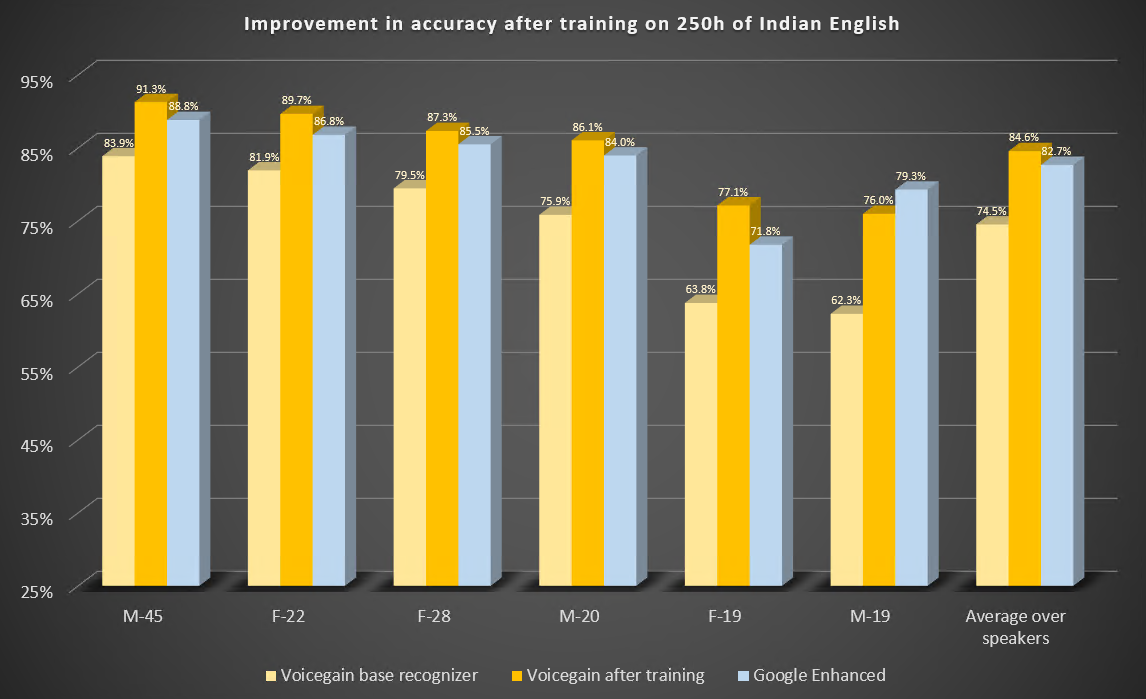
In this blog post we describe two case studies to illustrate improvements in speech-to-text or ASR recognition accuracy that can be expected from training of the underlying acoustic models. We trained our acoustic model to recognize Indian and Irish English better.
The Voicegain out-of-the-box Acoustic Model which is available as default on the Voicegain Platform had been trained to recognize mainly US English although our training data set did contain some British English audio. The training data did not contain Indian and Irish English, except for maybe accidental occurrences.
Both case studies were performed in an identical manner:
Here are the parameters of this study.
Here are the results of the benchmark before and after training. For comparison. we also include results from Google Enhanced Speech-to-Text.
Some observations:
Here are the parameters of this study.
Here are the results of the benchmark before and after training. We also include results from Google Enhanced Speech-to-Text.
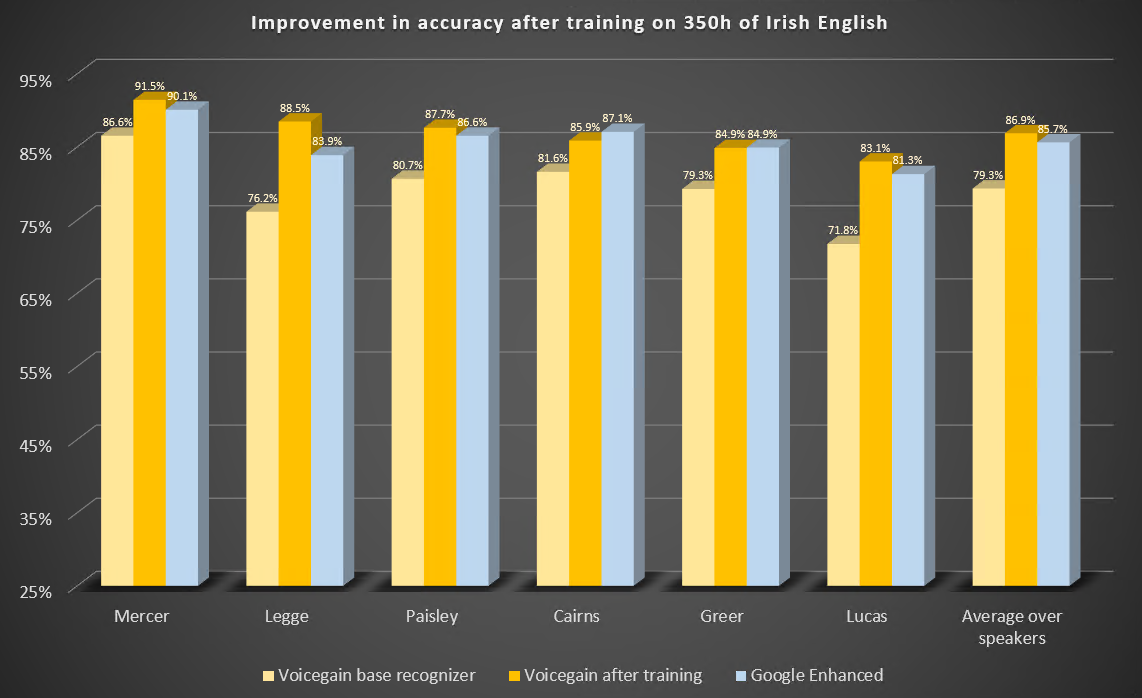
Some observations:
We have published 2 additional studies showing the benefits of Acoustic Model training:
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

In our previous post we described how Voicegain is providing grammar-based speech recognition to Twilio Programmable Voice platform via the Twilio Media Stream Feature.
Starting from release 1.16.0 of Voicegain Platform and API it possible to use Voicegain speech-to-text for speech transcription (without grammars) to achieve functionality like using TwiML <Gather>.
The reasons we think it will be attractive to Twilio users are:
Using Voicegain as an alternative to <Gather> will have similar steps to using Voicegain for grammar-based recognition - these are listed below.
This is done by invoking Voicegain async transcribe API: /asr/transcribe/async
Below is an example of the payload needed to start a new transcription session:
Some notes about the content of the request:
This request, if successful, will return the websocket url in the audio.stream.websocketUrl field. This value will be used in making a TwiML request.
Note, in the transcribe mode DTMF detection is currently not possible. Please let us know if this is something that would be critical to your use case.
After we have initiated a Voicegain ASR session, we can tell Twilio to open Media Streams connection to Voicegain. This is done by means of the following TwiML request:
Some notes about the content of the TwiML request:
Below is an example response from the transcription in case where "content" : {"full" : ["transcript"] } .

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices