
DALLAS, June 9, 2026 /PRNewswire-PRWeb/ -- Voicegain, a leading provider of AI-powered voice solutions for healthcare payers and contact centers, today announced the appointment of Tracy Puleo as Vice President of Sales.
In this role, Tracy will lead Voicegain's sales strategy, revenue growth initiatives, and customer acquisition efforts as the company rapidly scales its presence among health plans – Commercial, Medicaid and MA, third-party administrators (TPAs), and healthcare organizations seeking to transform member and provider experiences through generative Voice AI.
Tracy will lead sales for Voicegain Casey, a healthcare payer-focused software suite of three products that span the entire caller journey. They are (1) Conversational AI Voice Agents (2) Real-time Agent Assist (AI Co-Pilot) and (3) AI-Powered QA and Coaching Automation and Voice-of-Customer analytics. With the Voicegain Casey suite, healthcare organizations can elevate the member experience while lowering the operating costs of call centers.
Voicegain has rapidly emerged as a trusted AI partner for healthcare payer organizations with Voicegain Casey being used by over a dozen companies including Alliance Health, Samaritan Health, UnitedAg and Cottingham Buttler. Casey enables these organizations to augment their call center staff with real-time AI powered guidance and to automate routine member and provider inquiries like claims, eligibility and prior authorization status. Casey also analyzes 100% of all voice customer interactions and generates an automated QA score, extracts caller sentiment, CSAT and other Gen AI powered insights.
Voicegain Casey is built on the Voicegain platform, a leading privacy-first Voice AI platform that transcribes over 3 Billion minutes of audio for leading enterprises and mid-market companies. It is HIPAA, PCI and SOC-2 compliant and supports PII redaction, speaker diarization and 99 languages.
"Tracy is a proven healthcare sales leader with a strong track record of building relationships, delivering results, and helping healthcare organizations solve complex challenges," said Arun Santhebennur, Co-Founder and CEO of Voicegain. "Health plans face significant pressures to maintain and improve their HEDIS/STAR ratings and lower their administrative costs. They are looking for practical and proven AI solutions that improve member experience, increase operational efficiency, and drive measurable outcomes. Tracy's expertise and leadership will be instrumental in helping us accelerate our growth and expand our impact across the healthcare industry."
Tracy brings extensive experience in healthcare technology, payer engagement, customer experience, and enterprise sales and has led Sales for organizations like Zipari, Vimly Benefits, and ClickBoarding. Throughout her career, she has successfully partnered with health plans and healthcare organizations to implement innovative software solutions that increase member satisfaction, enhance operational performance, and support organizational growth.
"I am excited to join Voicegain at such a pivotal time," said Tracy Puleo. "Healthcare organizations are under tremendous pressure to improve member experiences while controlling costs and increasing efficiency. Voicegain Casey addresses these challenges in a meaningful way, and I look forward to working with our customers and partners to help them realize the full value of AI-driven engagement."
As Vice President of Sales, Tracy will focus on expanding Voicegain's customer base with healthcare payers, strengthening strategic partnerships, and helping organizations leverage AI to improve outcomes for members, providers, and contact center teams.
About Voicegain
Voicegain is a healthcare focused Voice AI company that offers AI Voice Agents, Real-time Agent Assist, Voice-of-Customer based analytics and automated quality assurance solutions. These products are designed to improve contact center efficiency and performance and elevate the member experiences.
Media Contact
Arun Santhebennur
Co-founder & CEO, Voicegain
Email: Arun@voicegain.ai
Website: https://www.voicegain.ai
Media Contact
Arun Santhebennur, Voicegain, 1 9725180863 701, arun@voicegain.ai, https://www.voicegain.ai/conversational-ivr
SOURCE Voicegain


Many of our customers have been asking us for help in benchmarking Voicegain speech-to-text recognizer (ASR) on their specific audio files. To make this benchmarking easier we have released a python script that accomplishes just that. With a single command line you can transcribe all audio files from the input directory and compare them against reference transcripts - calculating the WER for each file. You can also do a 2-way comparison of reference vs Voicegain transcript vs Google Speech-to-Text transcript.
The script and the documentation is available at: https://github.com/voicegain/platform/tree/master/utility-scripts/test-transcribe
See our benchmark blog post to give you an idea of what kind of accuracy to expect from the Voicegain recognizer.
Updated: Feb 28 2022
In this blog post we describe two case studies to illustrate improvements in speech-to-text or ASR recognition accuracy that can be expected from training of the underlying acoustic models. We trained our acoustic model to recognize Indian and Irish English better.
The Voicegain out-of-the-box Acoustic Model which is available as default on the Voicegain Platform had been trained to recognize mainly US English although our training data set did contain some British English audio. The training data did not contain Indian and Irish English, except for maybe accidental occurrences.
Both case studies were performed in an identical manner:
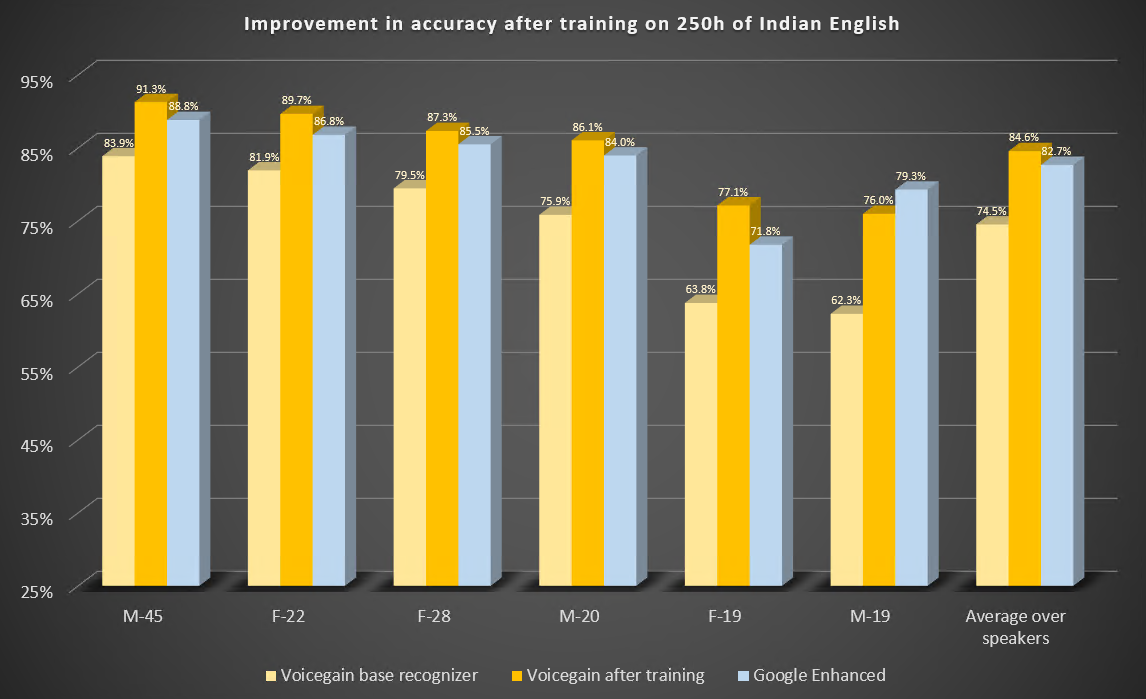
Here are the parameters of this study.
Here are the results of the benchmark before and after training. For comparison. we also include results from Google Enhanced Speech-to-Text.
Some observations:
Here are the parameters of this study.
Here are the results of the benchmark before and after training. We also include results from Google Enhanced Speech-to-Text.
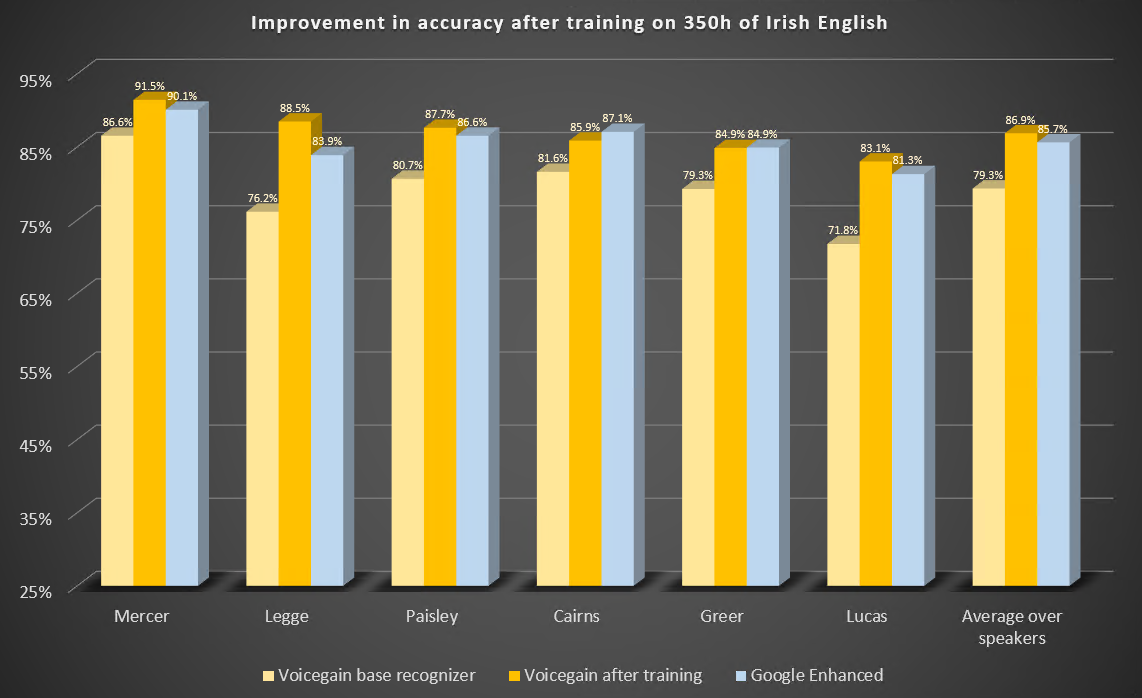
Some observations:
We have published 2 additional studies showing the benefits of Acoustic Model training:
1. Click here for instructions to access our live demo site.
2. If you are building a cool voice app and you are looking to test our APIs, click hereto sign up for a developer account and receive $50 in free credits
3. If you want to take Voicegain as your own AI Transcription Assistant to meetings, click here.

In our previous post we described how Voicegain is providing grammar-based speech recognition to Twilio Programmable Voice platform via the Twilio Media Stream Feature.
Starting from release 1.16.0 of Voicegain Platform and API it possible to use Voicegain speech-to-text for speech transcription (without grammars) to achieve functionality like using TwiML <Gather>.
The reasons we think it will be attractive to Twilio users are:
Using Voicegain as an alternative to <Gather> will have similar steps to using Voicegain for grammar-based recognition - these are listed below.
This is done by invoking Voicegain async transcribe API: /asr/transcribe/async
Below is an example of the payload needed to start a new transcription session:
Some notes about the content of the request:
This request, if successful, will return the websocket url in the audio.stream.websocketUrl field. This value will be used in making a TwiML request.
Note, in the transcribe mode DTMF detection is currently not possible. Please let us know if this is something that would be critical to your use case.
After we have initiated a Voicegain ASR session, we can tell Twilio to open Media Streams connection to Voicegain. This is done by means of the following TwiML request:
Some notes about the content of the TwiML request:
Below is an example response from the transcription in case where "content" : {"full" : ["transcript"] } .

We want to share a short video showing live transcription in action at CBC. This one is using our baseline Acoustic Model. No customizations were made, no hints used. This video gives an idea of what latency is achievable with real-time transcription.
Automated real-time transcription is a great solution for accommodating hearing impaired if no sign-language interpreter is available. I can be used, e.g., at churches to transcribe sermons, at conventions and meetings to transcribe talks, at educational institutions (schools, universities) to live transcribe lessons and lectures, etc.
Voicegain Platform provides a complete stack to support live transcription:
Very high accuracy - above that provided by Google, Amazon, and Microsoft Cloud speech-to-text - can be achieved through Acoustic Model customization.

Voicegain adds grammar-based speech recognition to Twilio Programmable Voice platform via the Twilio Media Stream Feature.
The difference between Voicegain speech recognition and Twilio TwiML <Gather> is:
When using Voicegain with Twilio, your application logic will need to handle callback requests from both Twilio and Voicegain.
Each recognition will involve two main steps described below:
This is done by invoking Voicegain async recognition API: /asr/recognize/async
Below is an example of the payload needed to start a new recognition session:
Some notes about the content of the request:
This request, if successful, will return the websocket url in the audio.stream.websocketUrl field. This value will be used in making a TwiML request.
Note, if the grammar is specified to recognize DTMF, the Voicegain recognizer will recognize DTMF signals included in the audio sent from Twilio Platform.
After we have initiated a Voicegain ASR session, we can tell Twilio to open Media Streams connection to Voicegain. This is done by means of the following TwiML request:
Some notes about the content of the TwiML request:
Below is an example response from the recognition. This response is from built-in phone grammar.

Some of the feedback that we received regarding the previously published benchmark data, see here and here, was concerning the fact that the Jason Kincaid data set contained some audio that produced terrible WER across all recognizers and in practice no one would user automated speech recognition on such files. That is true. In our opinion, there are very few use cases where WER worse than 20%, i.e. where on average 1 in every 5 words is recognized incorrectly, is acceptable.
What we have done for this blog post is we have removed from the reported set those benchmark files for which none on the recognizers tested could deliver WER 20% or less. This criterion resulted in removal of 10 files - 9 from the Jason Kincaid set of 44 and 1 file from the rev.ai set of 20. The files removed fall into 3 categories:
As you can see, Voicegain and Amazon recognizers are very evenly matched with average WER differing only by 0.02%, the same holds for Google Enhanced and Microsoft recognizer with the WER difference being only 0.04%. The WER of Google Standard is about twice of the other recognizers.

Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →
Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Donec sagittis sagittis ex, nec consequat sapien fermentum ut. Sed eget varius mauris. Etiam sed mi erat. Duis at porta metus, ac luctus neque.
Read more →Interested in customizing the ASR or deploying Voicegain on your infrastructure?

Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices