Build AI Voice Agents and Voice AI Apps with our Speech-to-Text and LLM APIs. Deploy in your Datacenter or use our Cloud. Transcribe and analyze meetings and call center phone calls in batch or real-time. Get summary, sentiment, named-entities and more. Get started today with a $50 credit.
Voice AI APIs for Developers • AI Voice Agents for Call Centers • AI Assistant for Meetings


Voicegain’s deep-learning-based ASR/STT models offer an unbeatable combination of accuracy, price and flexibility. These models can be deployed on-premise, in your VPC or invoked as a cloud service. We integrate out-of-the-box with leading contact center, video meeting and LLMs.
Our ASR is built on most recent advances in deep learning. We utilize end-to-end transformer-based deep neural networks and we have trained it with several tens of thousands of hours of diverse audio datasets.

APIs to embed transcription into your app and build voice bots accessible over telephony. Deploy Voicegain on your infrastructure (VPC, Datacenter) or use our cloud service

Get your private AI Meeting Assistant to automate meeting note taking. Always know who said what when and where! Integrates with video meeting platforms like Zoom, Microsoft Teams and Google Meet. Deploy in your datacenter or VPC.
Automate Quality Assurance and extract CX insights from voice interactions in contact center. White-label or Source Code License of UI available.

Voicegain, the leading Edge Voice AI platform for enterprises and Voice SaaS companies, is thrilled to announce the successful completion of a System and Organizational Control (SOC) 2 Type 2 Audit.
Read more →


New unified platform combines AI voice agent automation with Real-time agent assistance and Auto QA, enabling healthcare payers to reduce average handle time (AHT) and improve first contact resolution (FCR) in their call centers.
IRVING, Texas and SAN FRANCISCO, Jan. 7, 2026 /PRNewswire-PRWeb/ -- Voicegain, a leader in AI Voice Agents and Infrastructure, today announced the acquisition of TrampolineAI, a venture-backed healthcare payer-focused Contact Center AI company whose products supports thousands of member interactions. The acquisition unifies Voicegain's AI Voice Agent automation with Trampoline's real-time agent assistance and Auto QA capabilities, enabling healthcare payers to optimize their entire contact center operation—from fully automated interactions to AI-enhanced human agent support.
Healthcare payer contact centers face mounting pressure to reduce costs while improving member experience. The reasons vary from CMS pressure, Medicaid redeterminations, Medicare AEP volume and staffing shortages. The challenge lies in balancing automation for routine inquiries with personalized support for complex interactions. The combined Voicegain and TrampolineAI platform addresses this challenge by providing a comprehensive solution that spans the full spectrum of contact center needs—automating high-volume routine calls while empowering human agents with real-time intelligence for interactions that require specialized attention.
"We're seeing strong demand from healthcare payers for a production-ready Voice AI platform. TrampolineAI brings deep payer contact center expertise and deployments at scale, accelerating our mission at Voicegain." — Arun Santhebennur
Over the past two years, Voicegain has scaled Casey, an AI Voice Agent purpose-built for health plans, TPAs, utilization management, and other healthcare payer businesses. Casey answers and triages member and provider calls in health insurance payer call centers. After performing HIPAA validation, Casey automates routine caller intents related to claims, eligibility, coverage/benefits, and prior authorization. For calls requiring live assistance, Casey transfers the interaction context via screen pop to human agents.
TrampolineAI has developed a payer-focused Generative AI suite of contact center products—Assist, Analyze, and Auto QA—designed to enhance human agent efficiency and effectiveness. The platform analyzes conversations between members and agents in real-time, leveraging real-time transcription and Gen AI models. It provides real-time answers by scanning plan documents such as Summary of Benefits and Coverage (SBCs) and Summary Plan Descriptions (SPDs), fills agent checklists automatically, and generates payer-optimized interaction summaries. Since its founding, TrampolineAI has established deployments with leading TPAs and health plans, processing hundreds of thousands of member interactions.
"Our mission at Voicegain is to enable businesses to deploy private, mission-critical Voice AI at scale," said Arun Santhebennur, Co-founder and CEO of Voicegain. "As we enter 2026, we are seeing strong demand from healthcare payers for a comprehensive, production-ready Voice AI platform. The TrampolineAI team brings deep expertise in healthcare payer operations and contact center technology, and their solutions are already deployed at scale across multiple payer environments."
Through this acquisition, Voicegain expands the Casey platform with purpose-built capabilities for payer contact centers, including AI-assisted agent workflows, real-time sentiment analysis, and automated quality monitoring. TrampolineAI customers gain access to Voicegain's AI Voice Agents, enterprise-grade Voice AI infrastructure including real-time and batch transcription, and large-scale deployment capabilities, while continuing to receive uninterrupted service.
"We founded TrampolineAI to address the significant administrative cost challenges healthcare payers face by deploying Generative Voice AI in production environments at scale," said Mike Bourke, Founder and CEO of TrampolineAI. "Joining Voicegain allows us to accelerate that mission with their enterprise-grade infrastructure, engineering capabilities, and established customer base in the healthcare payer market. Together, we can deliver a truly comprehensive solution that serves the full range of contact center needs."
A TPA deploying TrampolineAI noted the platform's immediate impact, stating that the data and insights surfaced by the application were fantastic, allowing the organization to see trends and issues immediately across all incoming calls.
The combined platform positions Voicegain to deliver a complete contact center solution spanning IVA call automation, real-time transcription and agent assist, Medicare and Medicaid compliant automated QA, and next-generation analytics with native LLM analysis capabilities. Integration work is already in progress, and customers will begin seeing benefits of the combined platform in Q1 2026.
Following the acquisition, TrampolineAI founding team members Mike Bourke and Jason Fama have joined Voicegain's Advisory Board, where they will provide strategic guidance on product development and AI innovation for healthcare payer applications.
The terms of the acquisition were not disclosed.
About Voicegain
Voicegain offers healthcare payer-focused AI Voice Agents and a private Voice AI platform that enables enterprises to build, deploy, and scale voice-driven applications. Voicegain Casey is designed specifically for healthcare payers, supporting automated and assisted customer service interactions with enterprise-grade security, scalability, and compliance. For more information, visit voicegain.ai.
About TrampolineAI
TrampolineAI was a venture-backed voice AI company focused on healthcare payer solutions. The company applies Generative Voice AI to contact centers to improve operational efficiency, member experience, and compliance through real-time agent assist, sentiment analysis, and automated quality assurance technologies. For more information, visit trampolineai.com.
Media Contact:
Arun Santhebennur
Co-founder & CEO, Voicegain
Media Contact
Arun Santhebennur, Voicegain, 1 9725180863 701, arun@voicegain.ai, https://www.voicegain.ai
SOURCE Voicegain

Voicegain is releasing the results of its 2025 STT accuracy benchmark on an internally curated dataset of forty(40) call center audio files. This benchmark compares the accuracy of Voicegain's in-house STT models with that of the big cloud providers and also Voicegain's implementation of OpenAI's Whisper.
In the years past, we had published benchmarks that compared the accuracy of our in-house STT models against those of the big cloud providers. Here is the accuracy benchmark release in 2022 and the first release in 2021 and our second release in 2021. However the datasets we compared our STT models was a publicly available benchmark dataset that was on Medium and it included a wide variety of audio files - drawn from meetings, podcasts and telephony conversations.
Since 2023, Voicegain has focused on training and improving the accuracy of its in house Speech-to-Text AI models call center audio data. The benchmark we are releasing today is based on a Voicegain curated dataset of 40 audio files. These 40 files are from 8 different customers and from different industry verticals. For example two calls are consumer technology products, two are health insurance and one each in telecom, retail, manufacturing and consumer services. We did this to track how well the underlying acoustic models are trained on a variety of call center interactions.
In general Call Center audio data has the following characteristics
How was the accuracy of the engines calculated? We first created a golden transcript (human labeled) for each of the 40 files and calculated the Word Error Rate (WER) of each of the Speech-to-Text AI models that are included in the benchmark. The accuracy that is shown below is 1 - WER in percentage terms.
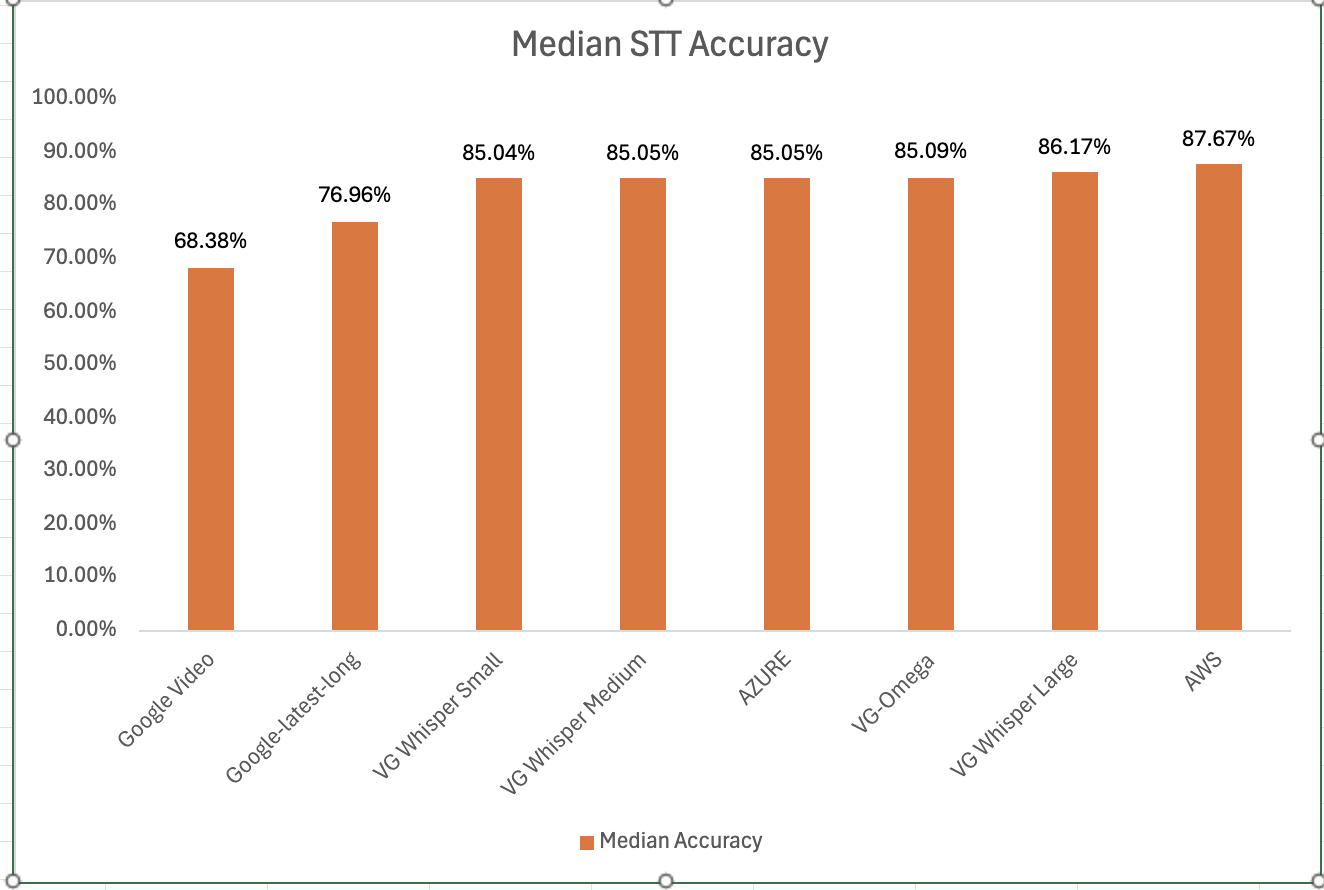
Most Accurate - Amazon AWS came out on top with an accuracy of 87.67%
Least Accurate - Google Video was the least trained acoustic model on our 8 kHz audio dataset. The accuracy was 68.38%
Most Accurate Voicegain Model - Voicegain-Whisper-Large-V3 is the most accurate model that Voicegain provides. Its accuracy was 86.17%
Accuracy of our inhouse Voicegain Omega Model - 85.09%. While this is slightly lower than Whisper-Large and AWS, it has two big advantages. The model is optimized for on-premise/pvt cloud deployment and it can further be trained on client audio data to get an accuracy that is higher.
One very important consideration for prospective customers is that while this benchmark is on the 40 files in this curated list, the actual results for their use-case may vary. The accuracy numbers shown above can be considered as a good starting point. With custom acoustic model training, the actual accuracy for a production use-case can be much higher.
There is also another important consideration for customers that want to deploy a Speech-to-Text model in their VPC or Datacenter. In addition to accuracy, the actual size of the model is very important. It is in this context that Voicegain Omega shines.
We also found that Voicegain Kappa - our Streaming STT engine has an accuracy that is very close to the accuracy of Voicegain Omega. The accuracy of Voicegain Kappa is less than 1% lower than Voicegain Omega.
If you are an enterprise that would like to reproduce this benchmark, please contact us over email (support@voicegain.ai). Please use your business email and share your full contact details. We would first need to qualify you, sign an NDA and then we can share the PII-redacted version of these audio call recordings.
“We selected Voicegain because they are accurate, affordable and easy to use. We deployed the entire platform in our datacenter in under 30 minutes.”
“We selected Voicegain for Sutherland CX360, our AI/ML SaaS offering to evaluate all of Sutherland’s CX interactions. We were looking for an accurate PCI-compliant ASR/STT offering for our enterprise customers and we found that in Voicegain..”
“Voicegain is amazing! They have a great ASR and a modern architecture. But what we really value is their prompt and timely support. We use both their MRCP ASR and STT APIs and they work great “
Interested in customizing the ASR or deploying Voicegain on your infrastructure?
Voicegain helps developers build awesome voice enabled apps by providing them with the most accurate, affordable and accessible Speech-to-Text platform.

'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices